


- © 2004 Canadian Medical Association or its licensors
Imagine that you're a busy family physician and that you've found a rare free moment to scan the recent literature. Reviewing your preferred digest of abstracts, you notice a study comparing emergency physicians' interpretation of chest radiographs with radiologists' interpretations.1 The article catches your eye because you have frequently found that your own reading of a radiograph differs from both the official radiologist reading and an unofficial reading by a different radiologist, and you've wondered about the extent of this disagreement and its implications.

Figure.

Figure.
Looking at the abstract, you find that the authors have reported the extent of agreement using the κ statistic. You recall that κ stands for “kappa” and that you have encountered this measure of agreement before, but your grasp of its meaning remains tentative. You therefore choose to take a quick glance at the authors' conclusions as reported in the abstract and to defer downloading and reviewing the full text of the article.
Practitioners, such as the family physician just described, may benefit from understanding measures of observer variability. For many studies in the medical literature, clinician readers will be interested in the extent of agreement among multiple observers. For example, do the investigators in a clinical study agree on the presence or absence of physical, radiographic or laboratory findings? Do investigators involved in a systematic overview agree on the validity of an article, or on whether the article should be included in the analysis? In perusing these types of studies, where investigators are interested in quantifying agreement, clinicians will often come across the kappa statistic.
In this article we present tips aimed at helping clinical learners to use the concepts of kappa when applying diagnostic tests in practice. The tips presented here have been adapted from approaches developed by educators experienced in teaching evidence-based medicine skills to clinicians.2 A related article, intended for people who teach these concepts to clinicians, is available online at www.cmaj.ca/cgi/content/full/171/11/1369/DC1.
Clinician learners' objectives
Defining the importance of kappa
-
Understand the difference between measuring agreement and measuring agreement beyond chance.
-
Understand the implications of different values of kappa.
Calculating kappa
-
Understand the basics of how the kappa score is calculated.
-
Understand the importance of “chance agreement” in estimating kappa.
Calculating chance agreement
-
Understand how to calculate the kappa score given different distributions of positive and negative results.
-
Understand that the more extreme the distributions of positive and negative results, the greater the agreement that will occur by chance alone.
-
Understand how to calculate chance agreement, agreement beyond chance and kappa for any set of assessments by 2 observers.
Tip 1: Defining the importance of kappa
A common stumbling block for clinicians is the basic concept of agreement beyond chance and, in turn, the importance of correcting for chance agreement. People making a decision on the basis of presence or absence of an element of the physical examination, such as Murphy's sign, will sometimes agree simply by chance. The kappa statistic corrects for this chance agreement and tells us how much of the possible agreement over and above chance the reviewers have achieved.
A simple example should help to clarify the importance of correcting for chance agreement. Two radiologists independently read the same 100 mammograms. Reader 1 is having a bad day and reads all the films as negative without looking at them in great detail. Reader 2 reads the films more carefully and identifies 4 of the 100 mammograms as positive (suspicious for malignancy). How would you characterize the level of agreement between these 2 radiologists?
The percent agreement between them is 96%, even though one of the readers has, on cursory review, decided to call all of the results negative. Hence, measuring the simple percent agreement overestimates the degree of clinically important agreement in a fashion that is misleading. The role of kappa is to indicate how much the 2 observers agree beyond the level of agreement that could be expected by chance. Table 1 presents a rating system that is commonly used as a guideline for evaluating kappa scores. Purely to illustrate the range of kappa scores that readers can expect to encounter, Table 2 gives some examples of commonly reported assessments and the kappa scores that resulted when investigators studied their reproducibility.
Table 2.
Table 1.
The bottom line
If clinicians neglect the possibility of chance agreement, they will come to misleading conclusions about the reproducibility of clinical tests. The kappa statistic allows us to measure agreement above and beyond that expected by chance alone. Examples of kappa scores for frequently ordered tests sometimes show surprisingly poor levels of agreement beyond chance.
Tip 2: Calculating kappa
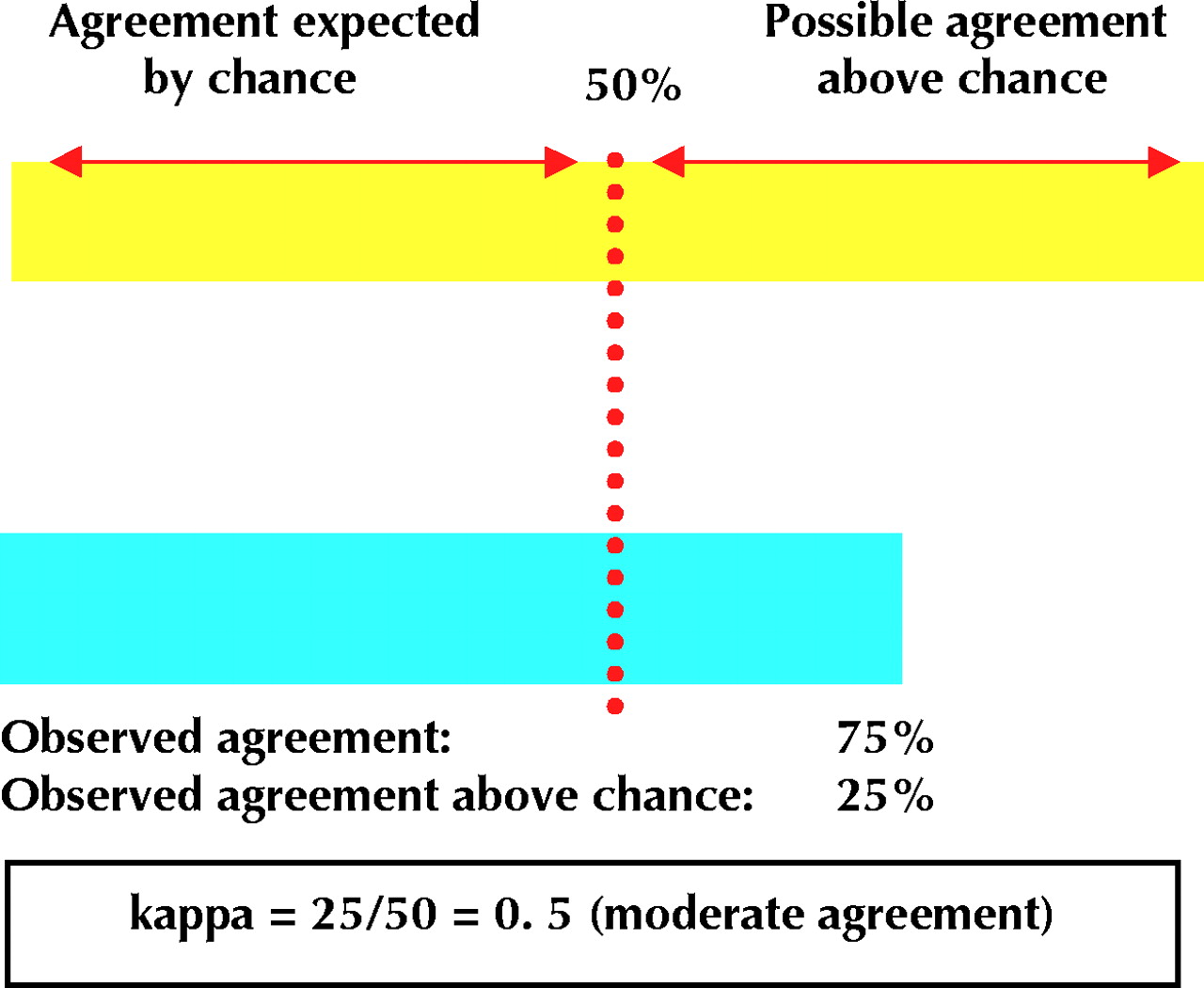
What is the maximum potential for agreement between 2 observers doing a clinical assessment, such as presence or absence of Murphy's sign in patients with abdominal pain? In Fig. 1, the upper horizontal bar represents 100% agreement between 2 observers. For the hypothetical situation represented in the figure, the estimated chance agreement between the 2 observers is 50%. This would occur if, for example, each of the 2 observers randomly called half of the assessments positive. Given this information, what is the possible agreement beyond chance?

Fig. 1: Two observers independently assess the presence or absence of a finding or outcome. Each observer determines that the finding is present in exactly 50% of the subjects. Their assessments agree in 75% of the cases. The yellow horizontal bar represents potential agreement (100%), and the turquoise bar represents actual agreement. The portion of each coloured bar that lies to the left of the dotted vertical line represents the agreement expected by chance (50%). The observed agreement above chance is half of the possible agreement above chance. The ratio of these 2 numbers is the kappa score.
The vertical line in Fig. 1 intersects the horizontal bars at the 50% point that we identified as the expected agreement by chance. All agreement to the right of this line corresponds to agreement beyond chance. Hence the maximum agreement beyond chance is 50% (100% – 50%).
The other number you need to calculate the kappa score is the degree of agreement beyond chance. The observed agreement, as shown by the lower horizontal bar in Fig. 1, is 75%, so the degree of agreement beyond chance is 25% (75% – 50%).
Kappa is calculated as the observed agreement beyond chance (25%) divided by the maximum agreement beyond chance (50%); here, kappa is 0.50.
The bottom line
Kappa allows us to measure agreement above and beyond that expected by chance alone. We calculate kappa by estimating the chance agreement and then comparing the observed agreement beyond chance with the maximum possible agreement beyond chance.
Tip 3: Calculating chance agreement
A conceptual understanding of kappa may still leave the actual calculations a mystery. The following example is intended for those who desire a more complete understanding of the kappa statistic.
Let us assume that 2 hopeless clinicians are assessing the presence of Murphy's sign in a group of patients. They have no idea what they are doing, and their evaluations are no better than blind guesses. Let us say they are each guessing the presence and absence of Murphy's sign in a 50:50 ratio: half the time they guess that Murphy's sign is present, and the other half that it is absent. If you were completing a 2 х 2 table, with these 2 clinicians evaluating the same 100 patients, how would the cells, on average, get filled in?
Fig. 2 represents the completed 2 х 2 table. Guessing at random, the 2 hopeless clinicians have agreed on the assessments of 50% of the patients. How did we arrive at the numbers shown in the table? According to the laws of chance, each clinician guesses that half of the 50 patients assessed as positive by the other clinician (i.e., 25 patients) have Murphy's sign.

Fig. 2: Agreement table for 2 hopeless clinicians who randomly guess whether Murphy's sign is present or absent in 100 patients with abdominal pain. Each clinician determines that half of the patients have a positive result. The numbers in each box reflect the number of patients in each agreement category.
How would this exercise work if the same 2 hopeless clinicians were to randomly guess that 60% of the patients had a positive result for Murphy's sign? Fig. 3 provides the answer in this situation. The clinicians would agree for 52 of the 100 patients (or 52% of the time) and would disagree for 48 of the patients. In a similar way, using 2 х 2 tables for higher and higher positive proportions (i.e., how often the observer makes the diagnosis), you can figure out how often the observers will, on average, agree by chance alone (as delineated in Table 3).
Table 3.
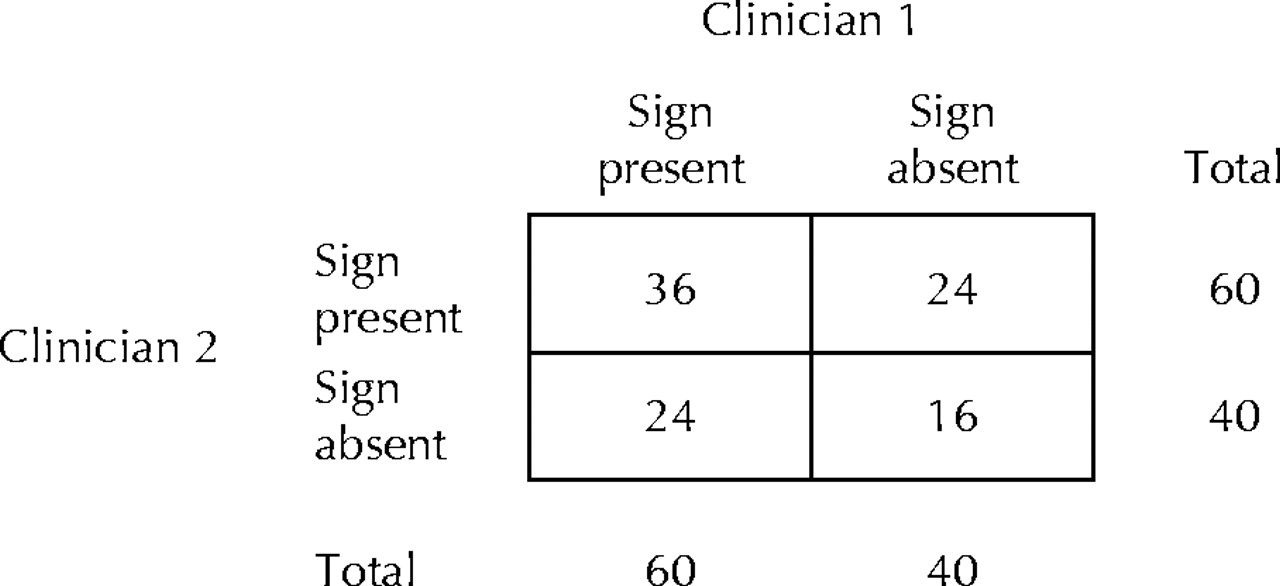
Fig. 3: As in Fig. 2, the 2 clinicians again guess at random whether Murphy's sign is present or absent. However, each clinician now guesses that the sign is present in 60 of the 100 patients. Under these circumstances, of the 60 patients for whom clinician 1 guesses that the sign is present, clinician 2 guesses that it is present in 60%; 60% of 60 is 36 patients. Of the 60 patients for whom clinician 1 guesses that the sign is present, clinician 2 guesses that it is absent in 40%; 40% of 60 is 24 patients. Of the 40 patients for whom clinician 1 guesses that the sign is absent, clinician 2 guesses that it is present in 60%; 60% of 40 is 24 patients. Of the 40 patients for whom clinician 1 guesses that the sign is absent, clinician 2 guesses that it is absent in 40%; 40% of 40 is 16 patients.
At this point, we have demonstrated 2 things. First, even if the reviewers have no idea what they are doing, there will be substantial agreement by chance alone. Second, the magnitude of the agreement by chance increases as the proportion of positive (or negative) assessments increases.
But how can we calculate kappa when the clinicians whose assessments are being compared are no longer “hopeless,” in other words, when their assessments reflect a level of expertise that one might actually encounter in practice? It's not very hard.
Let's take a simple example, returning to the premise that each of the 2 clinicians assesses Murphy's sign as being present in 50% of the patients. Here, we assume that the 2 clinicians now have some knowledge of Murphy's sign and their assessments are no longer random. Each decides that 50% of the patients have Murphy's sign and 50% do not, but they still don't agree on every patient. Rather, for 40 patients they agree that Murphy's sign is present, and for 40 patients they agree that Murphy's sign is absent. Thus, they agree on the diagnosis for 80% of the patients, and they disagree for 20% of the patients (see Fig. 4A). How do we calculate the kappa score in this situation?

Fig. 4: Two clinicians who have been trained to assess Murphy's sign in patients with abdominal pain do an actual assessment on 100 patients. A: A 2 х 2 table reflecting actual agreement between the 2 clinicians. B: A 2 х 2 table illustrating the correct approach to determining the kappa score. The numbers in parentheses correspond to the results that would be expected were each clinician randomly guessing that half of the patients had a positive result (as in Fig. 2).
Recall that if each clinician found that 50% of the patients had Murphy's sign but their decision about the presence of the sign in each patient was random, the clinicians would be in agreement 50% of the time, each cell of the 2 х 2 table would have 25 patients (as shown in Fig. 2), chance agreement would be 50%, and maximum agreement beyond chance would also be 50%.
The no-longer-hopeless clinicians' agreement on 80% of the patients is therefore 30% above chance. Kappa is a comparison of the observed agreement above chance with the maximum agreement above chance: 30%/50% = 60% of the possible agreement above chance, which gives these clinicians a kappa of 0.6, as shown in Fig. 4B.
Hence, to calculate kappa when only 2 alternatives are possible (e.g., presence or absence of a finding), you need just 2 numbers: the percentage of patients that the 2 assessors agreed on and the expected agreement by chance. Both can be determined by constructing a 2 х 2 table exactly as illustrated above.
The bottom line
Chance agreement is not always 50%; rather, it varies from one clinical situation to another. When the prevalence of a disease or outcome is low, 2 observers will guess that most patients are normal and the symptom of the disease is absent. This situation will lead to a high percentage of agreement simply by chance. When the prevalence is high, there will also be high apparent agreement, with most patients judged to exhibit the symptom. Kappa measures the agreement after correcting for this variable degree of chance agreement.
Conclusions
Armed with this understanding of kappa as a measure of agreement between different observers, you are able to return to the study of agreement in chest radiography interpretations between emergency physicians and radiologists1 in a more informed fashion. You learn from the abstract that the kappa score for overall agreement between the 2 classes of practitioners was 0.40, with a 95% confidence interval ranging from 0.35 to 0.46. This means that the agreement between emergency physicians and radiologists represented 40% of the potentially achievable agreement beyond chance. You understand that this kappa score would be conventionally considered to represent fair to moderate agreement but is inferior to many of the kappa values listed in Table 2. You are now much more confident about going to the full text of the article to review the methods and assess the clinical applicability of the results to your own patients.
The ability to understand measures of variability in data presented in clinical trials and systematic reviews is an important skill for clinicians. We have presented a series of tips developed and used by experienced teachers of evidence-based medicine for the purpose of facilitating such understanding.
-
Barratt A, Wyer PC, Hatala R, McGinn T, Dans AL, Keitz S, et al. Tips for learners of evidence-based medicine: 1. Relative risk reduction, absolute risk reduction and number needed to treat. CMAJ 2004;171(4):353-8.
-
Montori VM, Kleinbart J, Newman TB, Keitz S, Wyer PC, Moyer V, et al. Tips for learners of evidence-based medicine: 2. Measures of precision (confidence intervals). CMAJ 2004;171(6):611-5.
Articles to date in this series
Footnotes
-
This article has been peer reviewed.
Contributors: Thomas McGinn developed the original idea for tips 1 and 2 and, as principal author, oversaw and contributed to the writing of the manuscript. Thomas Newman and Roseanne Leipzig reviewed the manuscript at all phases of development and contributed to the writing as coauthors. Sheri Keitz used all of the tips as part of a live teaching exercise and submitted comments, suggestions and the possible variations that are described in the article. Peter Wyer reviewed and revised the final draft of the manuscript to achieve uniform adherence with format specifications. Gordon Guyatt developed the original idea for tip 3, reviewed the manuscript at all phases of development, contributed to the writing as a coauthor, and, as general editor, reviewed and revised the final draft of the manuscript to achieve accuracy and consistency of content.
Competing interests: None declared.
Correspondence to: Dr. Peter C. Wyer, 446 Pelhamdale Ave., Pelham NY 10803, USA; fax 914 738-9368; pwyeratt.net
In this issue

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Article tools






Jump to section
Related Articles
Cited By...
- Evaluation of evidence supporting NICE recommendations to change people's lifestyle in clinical practice: cross sectional survey
- A systematic review of medical and clinical research landscapes and quality in Malaysia and Indonesia [REALQUAMI]: the review protocol
- Changes in medication administration error rates associated with the introduction of electronic medication systems in hospitals: a multisite controlled before and after study
- An Interrater Reliability Study of Pulmonary Function Assessment With a Portable Spirometer
- Updated meta-analysis on prevention of venous thromboembolism in ambulatory cancer patients
- Comparison of informal caregiver and named nurse assessment of symptoms in elderly patients dying in hospital using the palliative outcome scale
- Paediatric advance care planning survey: a cross-sectional examination of congruence and discordance between adolescents with HIV/AIDS and their families
- The use of antibiotic prophylaxis in hip arthroscopy is under-reported and lacks evidence-based guidelines: a systematic review and survey
- Most elite athletes return to competition following operative management of meniscal tears: a systematic review
- Systematic review and meta-analysis of the effect of SGLT-2 inhibitors on microvascular outcomes in patients with type 2 diabetes: a review protocol
- Effects of advanced life support versus basic life support on the mortality rates of patients with trauma in prehospital settings: a study protocol for a systematic review and meta-analysis
- Effectiveness of a 'Do not interrupt bundled intervention to reduce interruptions during medication administration: a cluster randomised controlled feasibility study
- A systematic review and meta-analysis of trials of social network interventions in type 2 diabetes
- Surgical treatment of femoroacetabular impingement following slipped capital femoral epiphysis: A systematic review
- Answering medical questions at the point of care: a cross-sectional study comparing rapid decisions based on PubMed and Epistemonikos searches with evidence-based recommendations developed with the GRADE approach
- Prospective validation of a clinical decision rule to identify patients presenting to the emergency department with chest pain who can safely be removed from cardiac monitoring
- Athletic groin pain: a systematic review of surgical diagnoses, investigations and treatment
- Safety and efficacy of tranexamic acid in bleeding paediatric trauma patients: a systematic review protocol
- Return to Work and Sport Following High Tibial Osteotomy: A Systematic Review
- Early evidence reports positive outcomes after osteochondral grafts and chondrocyte transplantation in the hip: a systematic review
- Retractions in orthopaedic research: A systematic review
- Use of heparins in patients with cancer: individual participant data meta-analysis of randomised trials study protocol
- Childhood Cancer Mortality in India: Direct Estimates From a Nationally Representative Survey of Childhood Deaths
- No difference in outcome between early versus delayed weight-bearing following microfracture surgery of the hip, knee or ankle: a systematic review of outcomes and complications
- Expanding the scope of Critical Care Rapid Response Teams: a feasible approach to identify adverse events. A prospective observational cohort
- Non-visible versus visible haematuria and bladder cancer risk: a study of electronic records in primary care
- Computed tomography to assess risk of death in acute pulmonary embolism: a meta-analysis
- The Correlation Between Esophageal and Abdominal Pressures in Mechanically Ventilated Patients Undergoing Laparoscopic Surgery
- Determining the frequency and preventability of adverse drug reaction-related admissions to an Irish University Hospital: a cross-sectional study
- Periprocedural Heparin Bridging in Patients Receiving Vitamin K Antagonists: Systematic Review and Meta-Analysis of Bleeding and Thromboembolic Rates
- Authors response
- Errors in the administration of intravenous medications in hospital and the role of correct procedures and nurse experience
- Bedside Screening for Fistula Stenosis Should Be Tailored to the Site of the Arteriovenous Anastomosis
- In Search of an Optimal Bedside Screening Program for Arteriovenous Fistula Stenosis
- Homocysteine in Vascular Behcet Disease: A Meta-Analysis
- Visual Assessment of the Spine Bruckel Instrument, a Novel Status Tool to Reflect Appearance of the Spine in Patients with Ankylosing Spondylitis
- JAK2V617F mutation for the early diagnosis of Ph- myeloproliferative neoplasms in patients with venous thromboembolism: a meta-analysis
- Relationship Between Preventability of Death After Coronary Artery Bypass Graft Surgery and All-Cause Risk-Adjusted Mortality Rates
- Cardiovascular Risk Factors and Venous Thromboembolism: A Meta-Analysis
- Accuracy of Physical Examination in the Detection of Arteriovenous Fistula Stenosis
- Erythropoietin-receptor agonists in critically ill patients: a meta-analysis of randomized controlled trials
- Discordance in Perceptions of Barriers to Diabetes Care Between Patients and Primary Care and Secondary Care
- Thrombophilic abnormalities, oral contraceptives, and risk of cerebral vein thrombosis: a meta-analysis
- Not Working 3 Years After Breast Cancer: Predictors in a Population-Based Study
- Reliability of the Whiff Test in Clinical Practice
- Teaching evidence-based practice on foot
- Work absence after breast cancer diagnosis: a population-based study
- Teaching evidence-based practice on foot
- Kappa statistic
- Kappa statistic
- Kappa statistic
- Kappa statistic
- Editor's note
More in this TOC Section
Similar Articles

