





Abstract
Background Clinicians find standardized mean differences (SMDs) calculated from continuous outcomes difficult to interpret. Our objective was to determine the performance of methods in converting SMDs or means to odds ratios of treatment response and numbers needed to treat (NNTs) as more intuitive measures of treatment effect.
Methods Meta-epidemiological study of large-scale trials (≥100 patients per group) comparing active treatment with placebo, sham or non-intervention control. Trials had to use pain or global symptoms as continuous outcomes and report both the percentage of patients with treatment response and mean pain or symptom scores per group. For each trial, we calculated odds ratios of observed treatment response and NNTs and approximated these estimates from SMDs or means using all five currently available conversion methods by Hasselblad and Hedges (HH), Cox and Snell (CS), Furukawa (FU), Suissa (SU) and Kraemer and Kupfer (KK). We compared observed and approximated values within trials by deriving pooled ratios of odds ratios (RORs) and differences in NNTs. ROR <1 and positive differences in NNTs imply that approximations are more conservative than estimates calculated from observed treatment response. As measures of agreement, we calculated intraclass correlation coefficients.
Results A total of 29 trials in 13 654 patients were included. Four out of five methods were suitable (HH, CS, FU, SU), with RORs between 0.92 for SU [95% confidence interval (95% CI), 0.86–0.99] and 0.97 for HH (95% CI, 0.91–1.04) and differences in NNTs between 0.5 (95% CI, −0.1 to −1.6) and 1.3 (95% CI, 0.4–2.1). Intraclass correlation coefficients were ≥0.90 for these four methods, but ≤0.76 for the fifth method by KK (P for differences ≤0.027).
Conclusions The methods by HH, CS, FU and SU are suitable to convert summary treatment effects calculated from continuous outcomes into odds ratios of treatment response and NNTs, whereas the method by KK is unsuitable.
Introduction
Systematic reviews and meta-analyses of randomized trials are often used as a basis for clinical decision making. If outcomes are measured on a continuous scale, however, meta-analysts often find trials that have used a number of different instruments to measure the same underlying construct (e.g. depression, functional capacity or pain). The generation of a pooled overall estimate requires that all treatment effects are expressed in common units. The most popular approach is the use of standardized mean differences (SMDs), also known as effect sizes. SMDs are calculated by dividing observed differences in means by the corresponding standard deviation in each trial. Resulting standardized treatment effects are expressed as standard deviation units and should ensure that effects observed in different trials can be statistically combined regardless of the type of instrument used to assess clinical outcome.
Clinicians find SMDs non-intuitive and thus difficult to interpret.1 Instead, investigators have used responder analyses,2,3 dichotomizing continuous data based on a pre-specified cut-off score to classify patients into treatment responders, with a reduction in symptoms, which is important to patients (e.g. ≥30% decrease from baseline), and non-responders in each group. These dichotomized data could then be compared between groups using odds ratios, risk ratios, risk differences or numbers needed to treat (NNTs) or harm, all of which are likely to enhance interpretability for the clinician. Because choosing thresholds and reporting results as proportions have been widely adopted only recently, many trials, especially those published before 2000, report only continuous data. Five methods are available to approximate measures of dichotomized treatment response from SMDs or from group-specific means and corresponding standard deviations.4–8 To our knowledge, there are no empirical evaluations of the performance of all five methods against estimates calculated from actual treatment responses observed after dichotomization of original data in a large series of randomized trials. We therefore assembled a dataset of large trials performed in patients with osteoarthritis to determine the performance of all five methods in deriving odds ratios of treatment response and NNTs.
Methods
Literature search
We searched the Cochrane Central Register of Controlled Trials for entries from 1980 until 1 December 2010. The search strategy included text words and database-specific subject headings for knee and hip osteoarthritis (Supplementary Appendix A). One reviewer (B.d.C.) screened references for eligibility; a second reviewer (B.C.J.) screened a randomly selected sample of 20% of the references. Kappa as a measure of inter-observed agreement was 0.81.
Trial selection
We used a meta-epidemiological approach using data from trials that included patients with hip and/or knee osteoarthritis. We included placebo, sham or non-intervention control RCTs. Trials using an unpredictable allocation sequence were considered randomized; trials using potentially predictable allocation mechanisms, such as alternation or the allocation of patients according to their date of birth, were considered quasi-randomized. Trials had to report changes from baseline or final values at follow-up of pain and/or global symptoms, as well as dichotomized treatment response according to pre-determined criteria to define treatment response based on the same instrument. Studies had to include an average of at least 100 patients per group, with at least 75% of included patients diagnosed with osteoarthritis of the knee or hip. A two-arm trial with 110 patients in one arm and 95 patients in the second arm, for example, was eligible. Reports of trials were restricted to English language full-text peer-reviewed publications. The included trials were categorized according to the experimental intervention: acupuncture, viscosupplementation, food supplements, oral non-steroidal anti-inflammatory drugs (NSAIDs), topical NSAIDs, opioids, serotonin-norepinephrine reuptake inhibitors (SNRIs) and miscellaneous if only one trial examined an intervention (autologous conditioned serum, balneotherapy, ginger extract, collagen hydrolysate and paracetamol).
Data extraction and quality assessment
We extracted data from individual trials using a standardized form. Two out of three reviewers (B.d.C., B.C.J., T.T.), independently extracted the data in duplicate. Disagreements were resolved by consensus; a senior reviewer (A.W.S.R.), not otherwise involved in the data extraction process, made the final decision if reviewers failed to reach consensus. Concealment of treatment allocation was considered as adequate if investigators used central randomization, sequentially numbered, sealed, opaque envelopes or coded drug packs.9,10 Blinding of patients was considered adequate if experimental and control interventions were described as indistinguishable or if a double dummy technique was used.10 Analyses were considered to follow the intention-to-treat principle if all randomized patients were reported to be included in the analysis or if the reported numbers of patients randomized and analysed were identical.11
Standardized mean differences
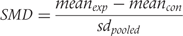
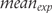 and
and 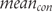 are mean values of the outcome in experimental and control groups, and
are mean values of the outcome in experimental and control groups, and 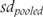 is the pooled standard deviation, which was in turn calculated as follows:
is the pooled standard deviation, which was in turn calculated as follows: 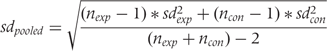
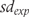 and
and 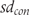 are standard deviations in experimental and control groups, and
are standard deviations in experimental and control groups, and 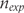 and
and 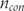 , the number of patients analysed. This formula accounts for potential between-group imbalances in number of patients and was used to calculate all SMDs in the present investigation. The following approximation may be used when number of patients in each group is approximately the same:
, the number of patients analysed. This formula accounts for potential between-group imbalances in number of patients and was used to calculate all SMDs in the present investigation. The following approximation may be used when number of patients in each group is approximately the same: 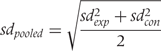
Conversion methods
The following sections present the methods used to convert results of continuous outcomes into dichotomized treatment response. Throughout, we refer to ‘observed’ values and ‘approximated’ values. Observed values are based on direct dichotomization of continuous data by trialists using a pre-specified cut-off score to classify patients into treatment responders and non-responders, with numbers or percentages reported in the published article. Approximated values are those derived from differences in means between groups (typically SMD) or from group means.
We used five different methods to convert continuous outcomes into dichotomized treatment effects. The first two methods by Hasselblad and Hedges4 and Cox and Snell5 allow the direct conversion of SMDs into odds ratios. The third method by Furukawa8,13 allows the conversion of SMDs into group-specific risks. The fourth method by Suissa6 uses group means to derive group-specific risks. The fifth method by Kraemer and Kupfer7 allows the direct conversion of SMDs into risk differences. Elaborations on these methods were recently published by Thorlund et al.1 and Anzures-Cabrera et al.14 Methods are summarized in the following paragraphs.
Hasselblad and Hedges’ method
Following Hasselblad and Hedges’ method, we multiplied the SMD and its standard error by 1.81 to calculate the log odds ratio lnOR and the corresponding standard error 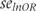 .4,15 The method is based on the assumption that mean scores in each group follow a logistic distribution (i.e. a near normal distribution) and that variances are equal between groups.
.4,15 The method is based on the assumption that mean scores in each group follow a logistic distribution (i.e. a near normal distribution) and that variances are equal between groups.
Cox and Snell’s method
Cox and Snell’s method is computationally similar to Hasselblad and Hedges’ method, but uses a different multiplication factor. We multiplied SMDs and their standard error by 1.65 to calculate log odds ratios and the corresponding standard errors.5,14 The method is based on the assumption that mean scores in each group follow a normal distribution and that variances are equal between groups.
Furukawa’s method
 as the probability of scores of included patients to be beyond the cut-off score
as the probability of scores of included patients to be beyond the cut-off score 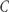 used to distinguish between patients with and without treatment response in a specific trial as follows:
used to distinguish between patients with and without treatment response in a specific trial as follows: 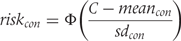
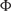 is the cumulative standard normal distribution.
is the cumulative standard normal distribution.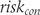 were used to derive the experimental group risk of treatment response
were used to derive the experimental group risk of treatment response 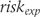
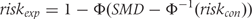
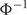 is the inverse of the cumulative standard normal distribution.
is the inverse of the cumulative standard normal distribution.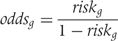
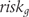 is the group-specific risk of treatment response, and derived the log odds ratio
is the group-specific risk of treatment response, and derived the log odds ratio 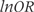 .
.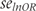 was calculated as follows1
was calculated as follows1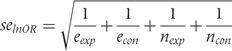
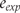 and
and 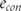 are the estimated numbers of events in experimental and control groups derived from risks
are the estimated numbers of events in experimental and control groups derived from risks 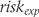 and
and 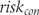 and the number of patients analysed
and the number of patients analysed 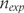 and
and 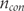 .
.Suissa’s method
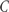 to derive a control group risk of treatment response and then calculates the experimental group risk of treatment response based on the calculated SMD, which in turn was derived using the pooled standard deviation. Suissa uses group-specific means and standard deviations and cut-off score
to derive a control group risk of treatment response and then calculates the experimental group risk of treatment response based on the calculated SMD, which in turn was derived using the pooled standard deviation. Suissa uses group-specific means and standard deviations and cut-off score 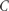 to derive the risk of treatment response in both groups rather than in the control group only.6 For the experimental group, this is as follows:
to derive the risk of treatment response in both groups rather than in the control group only.6 For the experimental group, this is as follows: 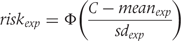
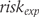 is the experimental group risk of treatment success,
is the experimental group risk of treatment success, 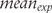 is the mean score for the experimental group and
is the mean score for the experimental group and 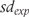 is its standard deviation. See (3) for corresponding calculations for the control group risk
is its standard deviation. See (3) for corresponding calculations for the control group risk 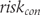 . If
. If 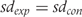 , then Furukawa’s and Suissa’s method will yield identical results. The more discrepant
, then Furukawa’s and Suissa’s method will yield identical results. The more discrepant  and
and  the more results will differ between Furukawa’s and Suissa’s method.
the more results will differ between Furukawa’s and Suissa’s method.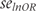 used for Furukawa’s method, as specified in (6), ignores that numbers of events in experimental and control groups were only estimated and not observed.14 Conversely, Suissa took this into account and suggested calculating the standard error of log odds ratio
used for Furukawa’s method, as specified in (6), ignores that numbers of events in experimental and control groups were only estimated and not observed.14 Conversely, Suissa took this into account and suggested calculating the standard error of log odds ratio 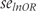 as follows:
as follows: 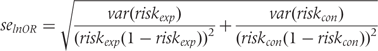
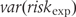 is the variance of
is the variance of 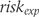 and
and 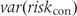 the variance of
the variance of 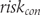 , with the group-specific variance estimated as follows:
, with the group-specific variance estimated as follows: 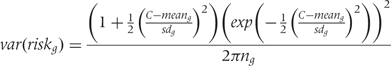
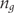 is the group number of participants,
is the group number of participants, 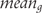 is the group mean score and
is the group mean score and 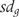 is its standard deviation, and
is its standard deviation, and 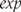 is the exponential function.
is the exponential function.Kraemer and Kupfer’s method
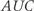 :
: 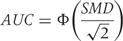
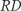 is calculated as follows:
is calculated as follows: 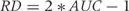
The same approach was used to estimate upper and lower limits of the 95% CI of the risk difference directly from the 95% CI of the SMD.
Calculation of odds ratios and NNTs
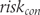 into the control group odds
into the control group odds 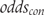 as shown in (5) and multiplied the control group odds by the odds ratio to derive the experimental group
as shown in (5) and multiplied the control group odds by the odds ratio to derive the experimental group 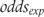 . For both, experimental and control group, we converted odds into risks as follows:
. For both, experimental and control group, we converted odds into risks as follows: 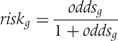
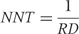
The methods by Furukawa and Suissa yielded group risks that were used to calculate risk differences. NNTs were calculated as in (13), and odds were derived as in (5) to calculate odds ratios. Kraemer and Kupfer’s method yielded risk differences, and NNTs were calculated as in (13). Then, we calculated the control group risk of treatment response 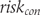 as shown in (3) and subtracted
as shown in (3) and subtracted 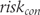 from the risk difference to derive the experimental group risk
from the risk difference to derive the experimental group risk 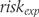 . Finally, we converted risks into odds as shown in (5) and derived odds ratios.
. Finally, we converted risks into odds as shown in (5) and derived odds ratios.
Comparison between observed and approximated values
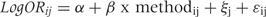
To determine whether results differed according to characteristics of clinical outcomes, we performed stratified analyses according to the following pre-specified characteristics: type of instrument (visual analogue scale for pain overall, WOMAC pain subscale, patient global assessment and other instruments if used in at least two of included trials); baseline risk, i.e. the percentage of patients with treatment response in the control group (≤20%, >20–≤40%, >40–≤60%, >60%); stringency of cut-off score used to define treatment response (>20–≤40%, >40–≤60%, >60–≤80% or >80% change from baseline). Then, we conducted stratified analyses according to pre-specified characteristics of trials for the most cited method by Hasselblad and Hedges4: treatment benefit observed in the trial (small [SMD > −0.5] versus large [SMD ≤ −0.5]); type of intervention (drug versus other interventions; complementary medicine versus other interventions); trial size (<200 patients per group versus ≥200 patients per group); risk of bias (blinding of patient and therapist; concealment of allocation; analysis according to the intention-to-treat principle). Stratified analyses were accompanied by two-sided tests for interaction between characteristics and the logROR and tests for linear trend in case of ordered groups using random-effects meta-regression models with robust variance estimation.17 Then, we derived summary differences in risk differences using random-effects meta-regression with robust variance estimation and the corresponding τ2 for differences in risk differences using conventional meta-analysis as described above. The design factor was 0.62. A positive difference indicates that the approximated value overestimates the treatment effect. For both, logRORs and differences in risk differences, we calculated 95% prediction intervals (PI)18 using the restricted maximum likelihood estimator of τ2 for LogRORs and differences in risk differences. The 95% PI indicates the interval in which LogRORs or differences in risk differences of future trials will fall with 95% probability.
To compare NNTs, we calculated differences between approximated and observed NNTs. A positive difference indicated higher approximated NNTs than observed, hence an underestimation of the treatment effect. Differences in NNTs were not normally distributed, therefore we bootstrapped the median difference using bias correction and acceleration19 to derive summary estimates and corresponding confidence intervals. For both odds ratios and NNTs, we graphically compared measures using scatter plots of observed versus approximated estimates with sizes of circles proportional to the inverse of the variance of observed estimates, and calculated corresponding intraclass correlation coefficients (ICCs) as measures of agreement.20 The 95% CIs of individual ICCs and P-values for pairwise comparisons of ICCs were derived using bootstrap resampling.
We also approximated odds ratios and NNTs from summary SMDs observed in the seven meta-analyses of interventions with two or more trials available: oral NSAIDs, topical NSAIDs, food supplements, acupuncture, opioids, SNRI, viscosupplementation. For each of these meta-analysis, we first derived a summary SMD using a DerSimonian and Laird random-effects model21 and then converted it into odds ratios and NNTs as described earlier in the text. To derive summary odds ratios of observed treatment response, we pooled trial-specific odds ratios for each meta-analysis using the same model. To derive summary NNTs based on observed treatment response, we first derived a summary risk ratio from trial-specific estimates for each meta-analysis. This summary risk ratio was multiplied with the median control group risk of treatment response observed in included trials to estimate the risk of treatment response in patients receiving the experimental intervention.22 Finally, we calculated risk differences between the estimated risk of treatment response in patients receiving the experimental intervention and the median control group risk and derived NNTs from the reciprocal of the risk difference. All P-values are two-sided. Analyses were performed in Stata Release 11 (Stata-Corp, College Station, TX).
RESULTS
Characteristics of included studies
Our search yielded 5290 references for screening (Supplementary Appendix B). Thirty-five reports describing 29 trials satisfied eligibility criteria. Supplementary Appendix C shows the characteristics of the included trials. In total, 13 654 patients contributed to the analysis. The treatment duration ranged from 1 day to 103 weeks (median 6 weeks), the mean age of patients from 57 to 70 years (median 62 years) and the percentage of females from 47% to 92% (median 65%). Thirteen trials (45%) reported adequate concealment of allocation, patients were appropriately blinded in 21 trials (72%) and analyses were performed according to the intention-to-treat principle in four trials (14%).
Conversion of continuous outcome into odds ratio
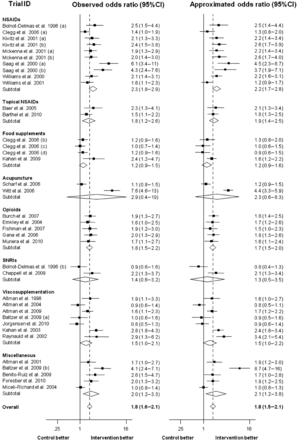
Figure 1 presents odds ratios of treatment response as observed (left) and as approximated from SMDs according to Hasselblad and Hedges based on differences in changes from baseline.4 For all trials, observed and approximated odds ratios showed the same direction of treatment effect and much the same magnitude. Figure 2 shows scatter plots comparing observed odds ratios on the x-axis with approximated odds ratios on the y-axis for SMDs derived from mean changes of symptom scores from baseline for all five methods. Agreement between observed and approximated odds ratios as determined by ICC were ≥0.90 for all methods, except for Kraemer and Kupfer’s (ICC = 0.76), which was inferior to the four other methods (P values for pairwise differences in ICC all ≤0.027). Supplementary Appendix D presents scatter plots and ICCs for odds ratios approximated from mean final values at follow-up.
Forest plot showing observed odds ratios and odds ratios approximated with Hasselblad and Hedges method. Analysis is based on change from baseline values. CI, confidence interval; NSAID, non-steroidal anti-inflamatory drug; SNRI, serotonin and norepinephrine reuptake inhibitor. Designators (a) to (d) identify multiple randomized comparisons from a single trial. Note that five trials contributed with two randomized comparisons and one trial contributed with four
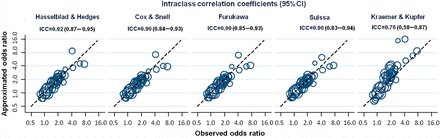
Scatter plots per conversion method showing the association between observed log odds ratios (x-axis) and approximated log odds ratio (y-axis) at the trial level. ICC, intraclass correlation coefficient; dashed lines indicate the line of identity between approximated and observed odds ratios; estimates lying above the line of identity indicate that the approximated odds ratio overestimates the observed treatment benefit; estimates lying below the line of identity indicate that the approximated odds ratio underestimates the observed treatment benefit. Approximated odds ratios were derived from change from baseline values; see Supplementary Appendix D for estimates based on final values at follow-up
Table 1 shows RORs pooled across all trials comparing approximated and observed estimates. Numerically, the approximation from mean changes from baseline according to Hasselblad and Hedges performed best, with an ROR of 0.97 (95% CI 0.91–1.04). The corresponding τ2 estimate of the LogROR was 0.00, accordingly the 95% PI corresponded to the 95% CI. However, CIs between RORs according to different methods overlapped widely. Except for the ROR based on the approximation by Kraemer and Kupfer, all RORs were near 1 with a τ2 of 0.00 and indicated that approximated odds ratios were on average somewhat more conservative than the reported data of observed treatment response. The ROR based on the approximation by Kraemer and Kupfer was 1.24 (95% CI, 1.09–1.40), reflecting an overestimation of the benefit of the experimental intervention; the corresponding τ2 was 0.06 and the 95% PI 0.74–2.07. Supplementary Appendix E presents RORs approximated from mean final values at follow-up.
Ratio of odds ratios according to each conversion method
| Method of conversion | ROR (95% CI) |
|---|---|
| Hasselblad and Hedges | 0.97 (0.91–1.04) |
| Cox and Snell | 0.92 (0.86–0.99) |
| Furukawa | 0.93 (0.87–0.99) |
| Suissa | 0.92 (0.86–0.99) |
| Kraemer and Kupfer | 1.24 (1.09–1.40) |
| Method of conversion | ROR (95% CI) |
|---|---|
| Hasselblad and Hedges | 0.97 (0.91–1.04) |
| Cox and Snell | 0.92 (0.86–0.99) |
| Furukawa | 0.93 (0.87–0.99) |
| Suissa | 0.92 (0.86–0.99) |
| Kraemer and Kupfer | 1.24 (1.09–1.40) |
ROR, ratio of odds ratios; CI, confidence interval.
ROR of 1 means no difference between approximated and observed odds ratios; an ROR >1 means that the approximated odds ratio overestimates the observed treatment response; an ROR<1 means that the approximated odds ratio underestimates the observed treatment response.
Approximated odds ratios were derived from change from baseline values; see Supplementary Appendix E for estimates based on final values at follow-up.
Ratio of odds ratios according to each conversion method
| Method of conversion | ROR (95% CI) |
|---|---|
| Hasselblad and Hedges | 0.97 (0.91–1.04) |
| Cox and Snell | 0.92 (0.86–0.99) |
| Furukawa | 0.93 (0.87–0.99) |
| Suissa | 0.92 (0.86–0.99) |
| Kraemer and Kupfer | 1.24 (1.09–1.40) |
| Method of conversion | ROR (95% CI) |
|---|---|
| Hasselblad and Hedges | 0.97 (0.91–1.04) |
| Cox and Snell | 0.92 (0.86–0.99) |
| Furukawa | 0.93 (0.87–0.99) |
| Suissa | 0.92 (0.86–0.99) |
| Kraemer and Kupfer | 1.24 (1.09–1.40) |
ROR, ratio of odds ratios; CI, confidence interval.
ROR of 1 means no difference between approximated and observed odds ratios; an ROR >1 means that the approximated odds ratio overestimates the observed treatment response; an ROR<1 means that the approximated odds ratio underestimates the observed treatment response.
Approximated odds ratios were derived from change from baseline values; see Supplementary Appendix E for estimates based on final values at follow-up.
Table 2 presents stratified analyses of RORs according to probability of treatment response in the control group. For all but Kraemer and Kupfer’s method, RORs were near 1 for probabilities >20–60%. For probabilities of ≤20%, approximated estimates became conservative, whereas for probabilities >60%, approximations became overoptimistic. However, 95% CIs overlapped widely, and tests for trend were negative. The method by Kraemer and Kupfer appeared particularly overoptimistic for probabilities of ≤40%, and the test for trend was positive (P = 0.02).
Stratified analysis comparing approximated odds ratio with observed odds ratio according to observed baseline risk
| Method | Observed baseline risk | Number of comparisons | Number of patients | ROR (95% CI) | P for trend |
|---|---|---|---|---|---|
| Hasselblad and Hedges | ≤20% | 6 | 2403 | 0.89 (0.73–1.09) | 0.78 |
| >20%–≤40% | 13 | 4723 | 1.05 (0.94–1.17) | ||
| >40%–≤60% | 17 | 6193 | 0.94 (0.86–1.04) | ||
| >60% | 1 | 335 | 1.15 (0.77–1.72) | ||
| Cox and Snell | ≤20% | 6 | 2403 | 0.82 (0.66–1.02) | 0.38 |
| >20%–≤40% | 13 | 4723 | 1.00 (0.90–1.10) | ||
| >40%–≤60% | 17 | 6193 | 0.92 (0.84–1.00) | ||
| >60% | 1 | 335 | 1.16 (0.79–1.71) | ||
| Furukawa | ≤20% | 6 | 2403 | 0.84 (0.69–1.03) | 0.73 |
| >20%–≤40% | 13 | 4723 | 1.01 (0.90–1.14) | ||
| >40%–≤60% | 17 | 6193 | 0.91 (0.83–0.99) | ||
| >60% | 1 | 335 | 1.16 (0.75–1.80) | ||
| Suissa | ≤20% | 6 | 2403 | 0.87 (0.69–1.10) | 0.70 |
| >20%–≤40% | 13 | 4723 | 1.01 (0.91–1.12) | ||
| >40%–≤60% | 17 | 6193 | 0.92 (0.85–1.00) | ||
| >60% | 1 | 335 | 1.16 (0.77–1.75) | ||
| Kraemer and Kupfer | ≤20% | 6 | 2403 | 1.45 (1.08–1.94) | 0.02 |
| >20%–≤40% | 13 | 4723 | 1.41 (1.14–1.76) | ||
| >40%–≤60% | 17 | 6193 | 1.04 (0.95–1.14) | ||
| >60% | 1 | 335 | 1.11 (0.71–1.73) |
| Method | Observed baseline risk | Number of comparisons | Number of patients | ROR (95% CI) | P for trend |
|---|---|---|---|---|---|
| Hasselblad and Hedges | ≤20% | 6 | 2403 | 0.89 (0.73–1.09) | 0.78 |
| >20%–≤40% | 13 | 4723 | 1.05 (0.94–1.17) | ||
| >40%–≤60% | 17 | 6193 | 0.94 (0.86–1.04) | ||
| >60% | 1 | 335 | 1.15 (0.77–1.72) | ||
| Cox and Snell | ≤20% | 6 | 2403 | 0.82 (0.66–1.02) | 0.38 |
| >20%–≤40% | 13 | 4723 | 1.00 (0.90–1.10) | ||
| >40%–≤60% | 17 | 6193 | 0.92 (0.84–1.00) | ||
| >60% | 1 | 335 | 1.16 (0.79–1.71) | ||
| Furukawa | ≤20% | 6 | 2403 | 0.84 (0.69–1.03) | 0.73 |
| >20%–≤40% | 13 | 4723 | 1.01 (0.90–1.14) | ||
| >40%–≤60% | 17 | 6193 | 0.91 (0.83–0.99) | ||
| >60% | 1 | 335 | 1.16 (0.75–1.80) | ||
| Suissa | ≤20% | 6 | 2403 | 0.87 (0.69–1.10) | 0.70 |
| >20%–≤40% | 13 | 4723 | 1.01 (0.91–1.12) | ||
| >40%–≤60% | 17 | 6193 | 0.92 (0.85–1.00) | ||
| >60% | 1 | 335 | 1.16 (0.77–1.75) | ||
| Kraemer and Kupfer | ≤20% | 6 | 2403 | 1.45 (1.08–1.94) | 0.02 |
| >20%–≤40% | 13 | 4723 | 1.41 (1.14–1.76) | ||
| >40%–≤60% | 17 | 6193 | 1.04 (0.95–1.14) | ||
| >60% | 1 | 335 | 1.11 (0.71–1.73) |
ROR of 1 means no difference between approximated and observed odds ratios; ROR >1 means that the approximated odds ratio overestimates the observed treatment benefit; ROR<1 means that the approximated odds ratio underestimates the observed treatment benefit.
Approximated odds ratios were derived using change from baseline values.
Stratified analysis comparing approximated odds ratio with observed odds ratio according to observed baseline risk
| Method | Observed baseline risk | Number of comparisons | Number of patients | ROR (95% CI) | P for trend |
|---|---|---|---|---|---|
| Hasselblad and Hedges | ≤20% | 6 | 2403 | 0.89 (0.73–1.09) | 0.78 |
| >20%–≤40% | 13 | 4723 | 1.05 (0.94–1.17) | ||
| >40%–≤60% | 17 | 6193 | 0.94 (0.86–1.04) | ||
| >60% | 1 | 335 | 1.15 (0.77–1.72) | ||
| Cox and Snell | ≤20% | 6 | 2403 | 0.82 (0.66–1.02) | 0.38 |
| >20%–≤40% | 13 | 4723 | 1.00 (0.90–1.10) | ||
| >40%–≤60% | 17 | 6193 | 0.92 (0.84–1.00) | ||
| >60% | 1 | 335 | 1.16 (0.79–1.71) | ||
| Furukawa | ≤20% | 6 | 2403 | 0.84 (0.69–1.03) | 0.73 |
| >20%–≤40% | 13 | 4723 | 1.01 (0.90–1.14) | ||
| >40%–≤60% | 17 | 6193 | 0.91 (0.83–0.99) | ||
| >60% | 1 | 335 | 1.16 (0.75–1.80) | ||
| Suissa | ≤20% | 6 | 2403 | 0.87 (0.69–1.10) | 0.70 |
| >20%–≤40% | 13 | 4723 | 1.01 (0.91–1.12) | ||
| >40%–≤60% | 17 | 6193 | 0.92 (0.85–1.00) | ||
| >60% | 1 | 335 | 1.16 (0.77–1.75) | ||
| Kraemer and Kupfer | ≤20% | 6 | 2403 | 1.45 (1.08–1.94) | 0.02 |
| >20%–≤40% | 13 | 4723 | 1.41 (1.14–1.76) | ||
| >40%–≤60% | 17 | 6193 | 1.04 (0.95–1.14) | ||
| >60% | 1 | 335 | 1.11 (0.71–1.73) |
| Method | Observed baseline risk | Number of comparisons | Number of patients | ROR (95% CI) | P for trend |
|---|---|---|---|---|---|
| Hasselblad and Hedges | ≤20% | 6 | 2403 | 0.89 (0.73–1.09) | 0.78 |
| >20%–≤40% | 13 | 4723 | 1.05 (0.94–1.17) | ||
| >40%–≤60% | 17 | 6193 | 0.94 (0.86–1.04) | ||
| >60% | 1 | 335 | 1.15 (0.77–1.72) | ||
| Cox and Snell | ≤20% | 6 | 2403 | 0.82 (0.66–1.02) | 0.38 |
| >20%–≤40% | 13 | 4723 | 1.00 (0.90–1.10) | ||
| >40%–≤60% | 17 | 6193 | 0.92 (0.84–1.00) | ||
| >60% | 1 | 335 | 1.16 (0.79–1.71) | ||
| Furukawa | ≤20% | 6 | 2403 | 0.84 (0.69–1.03) | 0.73 |
| >20%–≤40% | 13 | 4723 | 1.01 (0.90–1.14) | ||
| >40%–≤60% | 17 | 6193 | 0.91 (0.83–0.99) | ||
| >60% | 1 | 335 | 1.16 (0.75–1.80) | ||
| Suissa | ≤20% | 6 | 2403 | 0.87 (0.69–1.10) | 0.70 |
| >20%–≤40% | 13 | 4723 | 1.01 (0.91–1.12) | ||
| >40%–≤60% | 17 | 6193 | 0.92 (0.85–1.00) | ||
| >60% | 1 | 335 | 1.16 (0.77–1.75) | ||
| Kraemer and Kupfer | ≤20% | 6 | 2403 | 1.45 (1.08–1.94) | 0.02 |
| >20%–≤40% | 13 | 4723 | 1.41 (1.14–1.76) | ||
| >40%–≤60% | 17 | 6193 | 1.04 (0.95–1.14) | ||
| >60% | 1 | 335 | 1.11 (0.71–1.73) |
ROR of 1 means no difference between approximated and observed odds ratios; ROR >1 means that the approximated odds ratio overestimates the observed treatment benefit; ROR<1 means that the approximated odds ratio underestimates the observed treatment benefit.
Approximated odds ratios were derived using change from baseline values.
Table 3 presents stratified analyses of RORs according to the stringency of the thresholds used to define treatment response—the extent of symptom reduction required for a patient to be considered a treatment responder. For all methods except Kraemer and Kupfer’s,7 RORs were ∼1 for all thresholds. Kraemer and Kupfer’s approximation became increasingly overoptimistic with more extreme thresholds used to define treatment response (test for interaction P = 0.08).
Stratified analysis comparing approximated odds ratios with observed odds ratio according to cut-off score used to generate observed odds ratio
| Method | Cut-off score as percentage change from baseline | Number of comparisons | Number of patients | ROR (95% CI) | P for trend |
|---|---|---|---|---|---|
| Hasselblad and Hedges | >20%–≤40% | 9 | 3208 | 0.96 (0.85–1.09) | 0.76 |
| >40%–≤60% | 17 | 5968 | 0.96 (0.86–1.08) | ||
| >60%–<80% | 4 | 1541 | 1.00 (0.79–1.26) | ||
| Cox and Snell | >20%–≤40% | 9 | 3208 | 0.93 (0.83–1.05) | 0.96 |
| >40%–≤60% | 17 | 5968 | 0.91 (0.81–1.02) | ||
| >60%–<80% | 4 | 1541 | 0.94 (0.74–1.18) | ||
| Furukawa | >20%–≤40% | 9 | 3208 | 0.92 (0.81–1.06) | 0.77 |
| >40%–≤60% | 17 | 5968 | 0.92 (0.83–1.02) | ||
| >60%–<80% | 4 | 1541 | 0.97 (0.72–1.31) | ||
| Suissa | >20%–≤40% | 9 | 3208 | 0.96 (0.84–1.08) | 0.79 |
| >40%–≤60% | 17 | 5968 | 0.94 (0.85–1.04) | ||
| >60%–<80% | 4 | 1541 | 1.01 (0.73–1.40) | ||
| Kraemer and Kupfer | >20%–≤40% | 9 | 3208 | 1.10 (0.96–1.27) | 0.08 |
| >40%–≤60% | 17 | 5968 | 1.25 (1.06–1.47) | ||
| >60%–<80% | 4 | 1541 | 1.83 (1.01–3.31) |
| Method | Cut-off score as percentage change from baseline | Number of comparisons | Number of patients | ROR (95% CI) | P for trend |
|---|---|---|---|---|---|
| Hasselblad and Hedges | >20%–≤40% | 9 | 3208 | 0.96 (0.85–1.09) | 0.76 |
| >40%–≤60% | 17 | 5968 | 0.96 (0.86–1.08) | ||
| >60%–<80% | 4 | 1541 | 1.00 (0.79–1.26) | ||
| Cox and Snell | >20%–≤40% | 9 | 3208 | 0.93 (0.83–1.05) | 0.96 |
| >40%–≤60% | 17 | 5968 | 0.91 (0.81–1.02) | ||
| >60%–<80% | 4 | 1541 | 0.94 (0.74–1.18) | ||
| Furukawa | >20%–≤40% | 9 | 3208 | 0.92 (0.81–1.06) | 0.77 |
| >40%–≤60% | 17 | 5968 | 0.92 (0.83–1.02) | ||
| >60%–<80% | 4 | 1541 | 0.97 (0.72–1.31) | ||
| Suissa | >20%–≤40% | 9 | 3208 | 0.96 (0.84–1.08) | 0.79 |
| >40%–≤60% | 17 | 5968 | 0.94 (0.85–1.04) | ||
| >60%–<80% | 4 | 1541 | 1.01 (0.73–1.40) | ||
| Kraemer and Kupfer | >20%–≤40% | 9 | 3208 | 1.10 (0.96–1.27) | 0.08 |
| >40%–≤60% | 17 | 5968 | 1.25 (1.06–1.47) | ||
| >60%–<80% | 4 | 1541 | 1.83 (1.01–3.31) |
ROR of 1 means no difference between approximated and observed odds ratios; ROR >1 means that the approximated odds ratio overestimates the observed treatment benefit; ROR<1 means that the approximated odds ratio underestimates the observed treatment benefit.
Approximated odds ratios were derived using change from baseline values.
Stratified analysis comparing approximated odds ratios with observed odds ratio according to cut-off score used to generate observed odds ratio
| Method | Cut-off score as percentage change from baseline | Number of comparisons | Number of patients | ROR (95% CI) | P for trend |
|---|---|---|---|---|---|
| Hasselblad and Hedges | >20%–≤40% | 9 | 3208 | 0.96 (0.85–1.09) | 0.76 |
| >40%–≤60% | 17 | 5968 | 0.96 (0.86–1.08) | ||
| >60%–<80% | 4 | 1541 | 1.00 (0.79–1.26) | ||
| Cox and Snell | >20%–≤40% | 9 | 3208 | 0.93 (0.83–1.05) | 0.96 |
| >40%–≤60% | 17 | 5968 | 0.91 (0.81–1.02) | ||
| >60%–<80% | 4 | 1541 | 0.94 (0.74–1.18) | ||
| Furukawa | >20%–≤40% | 9 | 3208 | 0.92 (0.81–1.06) | 0.77 |
| >40%–≤60% | 17 | 5968 | 0.92 (0.83–1.02) | ||
| >60%–<80% | 4 | 1541 | 0.97 (0.72–1.31) | ||
| Suissa | >20%–≤40% | 9 | 3208 | 0.96 (0.84–1.08) | 0.79 |
| >40%–≤60% | 17 | 5968 | 0.94 (0.85–1.04) | ||
| >60%–<80% | 4 | 1541 | 1.01 (0.73–1.40) | ||
| Kraemer and Kupfer | >20%–≤40% | 9 | 3208 | 1.10 (0.96–1.27) | 0.08 |
| >40%–≤60% | 17 | 5968 | 1.25 (1.06–1.47) | ||
| >60%–<80% | 4 | 1541 | 1.83 (1.01–3.31) |
| Method | Cut-off score as percentage change from baseline | Number of comparisons | Number of patients | ROR (95% CI) | P for trend |
|---|---|---|---|---|---|
| Hasselblad and Hedges | >20%–≤40% | 9 | 3208 | 0.96 (0.85–1.09) | 0.76 |
| >40%–≤60% | 17 | 5968 | 0.96 (0.86–1.08) | ||
| >60%–<80% | 4 | 1541 | 1.00 (0.79–1.26) | ||
| Cox and Snell | >20%–≤40% | 9 | 3208 | 0.93 (0.83–1.05) | 0.96 |
| >40%–≤60% | 17 | 5968 | 0.91 (0.81–1.02) | ||
| >60%–<80% | 4 | 1541 | 0.94 (0.74–1.18) | ||
| Furukawa | >20%–≤40% | 9 | 3208 | 0.92 (0.81–1.06) | 0.77 |
| >40%–≤60% | 17 | 5968 | 0.92 (0.83–1.02) | ||
| >60%–<80% | 4 | 1541 | 0.97 (0.72–1.31) | ||
| Suissa | >20%–≤40% | 9 | 3208 | 0.96 (0.84–1.08) | 0.79 |
| >40%–≤60% | 17 | 5968 | 0.94 (0.85–1.04) | ||
| >60%–<80% | 4 | 1541 | 1.01 (0.73–1.40) | ||
| Kraemer and Kupfer | >20%–≤40% | 9 | 3208 | 1.10 (0.96–1.27) | 0.08 |
| >40%–≤60% | 17 | 5968 | 1.25 (1.06–1.47) | ||
| >60%–<80% | 4 | 1541 | 1.83 (1.01–3.31) |
ROR of 1 means no difference between approximated and observed odds ratios; ROR >1 means that the approximated odds ratio overestimates the observed treatment benefit; ROR<1 means that the approximated odds ratio underestimates the observed treatment benefit.
Approximated odds ratios were derived using change from baseline values.
Table 4 presents a stratified analysis according to type of instrument used to assess symptom severity. There was some variation across instruments for all methods, but confidence intervals overlapped widely, and tests for interaction between ROR and type of instrument were negative (P for interaction ≥ 0.23). For all methods, except Kraemer and Kupfer’s, approximated odds ratios were more conservative or much the same as observed odds ratios, with RORs close to 1. Kraemer and Kupfer’s method approximations again overestimated odds ratios. Table 5 presents stratified analyses according to characteristics of interventions and trials for Hasselblad and Hedges’ method based on change from baseline data. There was no evidence to suggest that RORs differed according to any of these characteristics (P for interaction ≥ 0.66).
Stratified analysis comparing approximated odds ratio with observed odds ratio according to type of instrument
| Method | Outcome measure | Number of comparisons | Number of patients | ROR (95% CI) | P for interaction |
|---|---|---|---|---|---|
| Hasselblad and Hedges | Pain overall VAS | 9 | 3451 | 0.99 (0.87–1.13) | 0.75 |
| Patient global assessment | 7 | 3494 | 1.02 (0.90–1.16) | ||
| WOMAC pain | 6 | 3348 | 0.91 (0.79–1.04) | ||
| Pain on walking VAS | 3 | 1310 | 0.95 (0.75–1.21) | ||
| WOMAC global | 2 | 1310 | 0.80 (0.45–1.43) | ||
| Lequesne index | 2 | 841 | 1.01 (0.76–1.35) | ||
| Cox and Snell | Pain overall VAS | 9 | 3451 | 0.94 (0.83–1.07) | 0.86 |
| Patient global assessment | 7 | 3494 | 0.96 (0.85–1.08) | ||
| WOMAC pain | 6 | 3348 | 0.89 (0.78–1.01) | ||
| Pain on walking VAS | 3 | 1310 | 0.90 (0.72–1.14) | ||
| WOMAC global | 2 | 1310 | 0.74 (0.37–1.49) | ||
| Lequesne index | 2 | 841 | 0.98 (0.74–1.29) | ||
| Furukawa | Pain overall VAS | 9 | 3451 | 0.94 (0.82–1.08) | 0.93 |
| Patient global assessment | 7 | 3494 | 0.95 (0.83–1.08) | ||
| WOMAC pain | 6 | 3348 | 0.88 (0.78–1.00) | ||
| Pain on walking VAS | 3 | 1310 | 0.90 (0.69–1.18) | ||
| WOMAC global | 2 | 1310 | 0.76 (0.40–1.45) | ||
| Lequesne index | 2 | 841 | 0.98 (0.72–1.34) | ||
| Suissa | Pain overall VAS | 9 | 3451 | 0.95 (0.85–1.07) | |
| Patient global assessment | 7 | 3494 | 0.95 (0.84–1.07) | 0.93 | |
| WOMAC pain | 6 | 3348 | 0.90 (0.81–0.99) | ||
| Pain on walking VAS | 3 | 1310 | 0.90 (0.71–1.14) | ||
| WOMAC global | 2 | 1310 | 0.76 (0.40–1.45) | ||
| Lequesne index | 2 | 841 | 0.97 (0.75–1.26) | ||
| Kraemer and Kupfer | Pain overall VAS | 9 | 3451 | 1.31 (1.07–1.61) | 0.23 |
| Patient global assessment | 7 | 3494 | 1.36 (1.14–1.62) | ||
| WOMAC pain | 6 | 3348 | 0.97 (0.86–1.10) | ||
| Pain on walking VAS | 3 | 1310 | 1.23 (0.85–1.79) | ||
| WOMAC global | 2 | 1310 | 1.12 (0.88–1.42) | ||
| Lequesne index | 2 | 841 | 1.19 (0.87–1.62) |
| Method | Outcome measure | Number of comparisons | Number of patients | ROR (95% CI) | P for interaction |
|---|---|---|---|---|---|
| Hasselblad and Hedges | Pain overall VAS | 9 | 3451 | 0.99 (0.87–1.13) | 0.75 |
| Patient global assessment | 7 | 3494 | 1.02 (0.90–1.16) | ||
| WOMAC pain | 6 | 3348 | 0.91 (0.79–1.04) | ||
| Pain on walking VAS | 3 | 1310 | 0.95 (0.75–1.21) | ||
| WOMAC global | 2 | 1310 | 0.80 (0.45–1.43) | ||
| Lequesne index | 2 | 841 | 1.01 (0.76–1.35) | ||
| Cox and Snell | Pain overall VAS | 9 | 3451 | 0.94 (0.83–1.07) | 0.86 |
| Patient global assessment | 7 | 3494 | 0.96 (0.85–1.08) | ||
| WOMAC pain | 6 | 3348 | 0.89 (0.78–1.01) | ||
| Pain on walking VAS | 3 | 1310 | 0.90 (0.72–1.14) | ||
| WOMAC global | 2 | 1310 | 0.74 (0.37–1.49) | ||
| Lequesne index | 2 | 841 | 0.98 (0.74–1.29) | ||
| Furukawa | Pain overall VAS | 9 | 3451 | 0.94 (0.82–1.08) | 0.93 |
| Patient global assessment | 7 | 3494 | 0.95 (0.83–1.08) | ||
| WOMAC pain | 6 | 3348 | 0.88 (0.78–1.00) | ||
| Pain on walking VAS | 3 | 1310 | 0.90 (0.69–1.18) | ||
| WOMAC global | 2 | 1310 | 0.76 (0.40–1.45) | ||
| Lequesne index | 2 | 841 | 0.98 (0.72–1.34) | ||
| Suissa | Pain overall VAS | 9 | 3451 | 0.95 (0.85–1.07) | |
| Patient global assessment | 7 | 3494 | 0.95 (0.84–1.07) | 0.93 | |
| WOMAC pain | 6 | 3348 | 0.90 (0.81–0.99) | ||
| Pain on walking VAS | 3 | 1310 | 0.90 (0.71–1.14) | ||
| WOMAC global | 2 | 1310 | 0.76 (0.40–1.45) | ||
| Lequesne index | 2 | 841 | 0.97 (0.75–1.26) | ||
| Kraemer and Kupfer | Pain overall VAS | 9 | 3451 | 1.31 (1.07–1.61) | 0.23 |
| Patient global assessment | 7 | 3494 | 1.36 (1.14–1.62) | ||
| WOMAC pain | 6 | 3348 | 0.97 (0.86–1.10) | ||
| Pain on walking VAS | 3 | 1310 | 1.23 (0.85–1.79) | ||
| WOMAC global | 2 | 1310 | 1.12 (0.88–1.42) | ||
| Lequesne index | 2 | 841 | 1.19 (0.87–1.62) |
ROR of 1 means no difference between approximated and observed odds ratios; ROR >1 means that the approximated odds ratio overestimates the observed treatment benefit; ROR<1 means that the approximated odds ratio underestimates the observed treatment benefit.
Approximated odds ratios were derived using change from baseline values.
Stratified analysis comparing approximated odds ratio with observed odds ratio according to type of instrument
| Method | Outcome measure | Number of comparisons | Number of patients | ROR (95% CI) | P for interaction |
|---|---|---|---|---|---|
| Hasselblad and Hedges | Pain overall VAS | 9 | 3451 | 0.99 (0.87–1.13) | 0.75 |
| Patient global assessment | 7 | 3494 | 1.02 (0.90–1.16) | ||
| WOMAC pain | 6 | 3348 | 0.91 (0.79–1.04) | ||
| Pain on walking VAS | 3 | 1310 | 0.95 (0.75–1.21) | ||
| WOMAC global | 2 | 1310 | 0.80 (0.45–1.43) | ||
| Lequesne index | 2 | 841 | 1.01 (0.76–1.35) | ||
| Cox and Snell | Pain overall VAS | 9 | 3451 | 0.94 (0.83–1.07) | 0.86 |
| Patient global assessment | 7 | 3494 | 0.96 (0.85–1.08) | ||
| WOMAC pain | 6 | 3348 | 0.89 (0.78–1.01) | ||
| Pain on walking VAS | 3 | 1310 | 0.90 (0.72–1.14) | ||
| WOMAC global | 2 | 1310 | 0.74 (0.37–1.49) | ||
| Lequesne index | 2 | 841 | 0.98 (0.74–1.29) | ||
| Furukawa | Pain overall VAS | 9 | 3451 | 0.94 (0.82–1.08) | 0.93 |
| Patient global assessment | 7 | 3494 | 0.95 (0.83–1.08) | ||
| WOMAC pain | 6 | 3348 | 0.88 (0.78–1.00) | ||
| Pain on walking VAS | 3 | 1310 | 0.90 (0.69–1.18) | ||
| WOMAC global | 2 | 1310 | 0.76 (0.40–1.45) | ||
| Lequesne index | 2 | 841 | 0.98 (0.72–1.34) | ||
| Suissa | Pain overall VAS | 9 | 3451 | 0.95 (0.85–1.07) | |
| Patient global assessment | 7 | 3494 | 0.95 (0.84–1.07) | 0.93 | |
| WOMAC pain | 6 | 3348 | 0.90 (0.81–0.99) | ||
| Pain on walking VAS | 3 | 1310 | 0.90 (0.71–1.14) | ||
| WOMAC global | 2 | 1310 | 0.76 (0.40–1.45) | ||
| Lequesne index | 2 | 841 | 0.97 (0.75–1.26) | ||
| Kraemer and Kupfer | Pain overall VAS | 9 | 3451 | 1.31 (1.07–1.61) | 0.23 |
| Patient global assessment | 7 | 3494 | 1.36 (1.14–1.62) | ||
| WOMAC pain | 6 | 3348 | 0.97 (0.86–1.10) | ||
| Pain on walking VAS | 3 | 1310 | 1.23 (0.85–1.79) | ||
| WOMAC global | 2 | 1310 | 1.12 (0.88–1.42) | ||
| Lequesne index | 2 | 841 | 1.19 (0.87–1.62) |
| Method | Outcome measure | Number of comparisons | Number of patients | ROR (95% CI) | P for interaction |
|---|---|---|---|---|---|
| Hasselblad and Hedges | Pain overall VAS | 9 | 3451 | 0.99 (0.87–1.13) | 0.75 |
| Patient global assessment | 7 | 3494 | 1.02 (0.90–1.16) | ||
| WOMAC pain | 6 | 3348 | 0.91 (0.79–1.04) | ||
| Pain on walking VAS | 3 | 1310 | 0.95 (0.75–1.21) | ||
| WOMAC global | 2 | 1310 | 0.80 (0.45–1.43) | ||
| Lequesne index | 2 | 841 | 1.01 (0.76–1.35) | ||
| Cox and Snell | Pain overall VAS | 9 | 3451 | 0.94 (0.83–1.07) | 0.86 |
| Patient global assessment | 7 | 3494 | 0.96 (0.85–1.08) | ||
| WOMAC pain | 6 | 3348 | 0.89 (0.78–1.01) | ||
| Pain on walking VAS | 3 | 1310 | 0.90 (0.72–1.14) | ||
| WOMAC global | 2 | 1310 | 0.74 (0.37–1.49) | ||
| Lequesne index | 2 | 841 | 0.98 (0.74–1.29) | ||
| Furukawa | Pain overall VAS | 9 | 3451 | 0.94 (0.82–1.08) | 0.93 |
| Patient global assessment | 7 | 3494 | 0.95 (0.83–1.08) | ||
| WOMAC pain | 6 | 3348 | 0.88 (0.78–1.00) | ||
| Pain on walking VAS | 3 | 1310 | 0.90 (0.69–1.18) | ||
| WOMAC global | 2 | 1310 | 0.76 (0.40–1.45) | ||
| Lequesne index | 2 | 841 | 0.98 (0.72–1.34) | ||
| Suissa | Pain overall VAS | 9 | 3451 | 0.95 (0.85–1.07) | |
| Patient global assessment | 7 | 3494 | 0.95 (0.84–1.07) | 0.93 | |
| WOMAC pain | 6 | 3348 | 0.90 (0.81–0.99) | ||
| Pain on walking VAS | 3 | 1310 | 0.90 (0.71–1.14) | ||
| WOMAC global | 2 | 1310 | 0.76 (0.40–1.45) | ||
| Lequesne index | 2 | 841 | 0.97 (0.75–1.26) | ||
| Kraemer and Kupfer | Pain overall VAS | 9 | 3451 | 1.31 (1.07–1.61) | 0.23 |
| Patient global assessment | 7 | 3494 | 1.36 (1.14–1.62) | ||
| WOMAC pain | 6 | 3348 | 0.97 (0.86–1.10) | ||
| Pain on walking VAS | 3 | 1310 | 1.23 (0.85–1.79) | ||
| WOMAC global | 2 | 1310 | 1.12 (0.88–1.42) | ||
| Lequesne index | 2 | 841 | 1.19 (0.87–1.62) |
ROR of 1 means no difference between approximated and observed odds ratios; ROR >1 means that the approximated odds ratio overestimates the observed treatment benefit; ROR<1 means that the approximated odds ratio underestimates the observed treatment benefit.
Approximated odds ratios were derived using change from baseline values.
Stratified analysis comparing approximated odds ratio based on Hasselblad and Hedges method to observed odds ratio
| Stratified analysis | Number of comparisons | ROR (95% CI) | P for interaction |
|---|---|---|---|
| Overall | 37 | 0.97 (0.91–1.04) | |
| Treatment effect size | 0.70 | ||
| Small | 29 | 0.96 (0.91–1.01) | |
| Large | 8 | 1.02 (0.77–1.35) | |
| Drug intervention | 0.89 | ||
| Yes | 33 | 0.97 (0.92–1.02) | |
| No | 4 | 1.00 (0.63–1.58) | |
| Complementary medicine | 0.97 | ||
| Yes | 10 | 0.97 (0.79–1.19) | |
| No | 27 | 0.97 (0.92–1.03) | |
| Concealment adequate | 0.98 | ||
| Yes | 14 | 0.99 (0.86–1.14) | |
| Unclear | 23 | 0.96 (0.89–1.03) | |
| Blinding patient and therapist adequate | 0.97 | ||
| Yes | 8 | 0.97 (0.86–1.11) | |
| No | 29 | 0.97 (0.90–1.05) | |
| ITT performed | 0.69 | ||
| Yes | 6 | 1.00 (0.85–1.19) | |
| No | 31 | 0.97 (0.90–1.04) | |
| Trial size | 0.66 | ||
| <200 patients per group | 20 | 0.98 (0.88–1.10) | |
| ≥200 patients per group | 17 | 0.96 (0.88–1.04) |
| Stratified analysis | Number of comparisons | ROR (95% CI) | P for interaction |
|---|---|---|---|
| Overall | 37 | 0.97 (0.91–1.04) | |
| Treatment effect size | 0.70 | ||
| Small | 29 | 0.96 (0.91–1.01) | |
| Large | 8 | 1.02 (0.77–1.35) | |
| Drug intervention | 0.89 | ||
| Yes | 33 | 0.97 (0.92–1.02) | |
| No | 4 | 1.00 (0.63–1.58) | |
| Complementary medicine | 0.97 | ||
| Yes | 10 | 0.97 (0.79–1.19) | |
| No | 27 | 0.97 (0.92–1.03) | |
| Concealment adequate | 0.98 | ||
| Yes | 14 | 0.99 (0.86–1.14) | |
| Unclear | 23 | 0.96 (0.89–1.03) | |
| Blinding patient and therapist adequate | 0.97 | ||
| Yes | 8 | 0.97 (0.86–1.11) | |
| No | 29 | 0.97 (0.90–1.05) | |
| ITT performed | 0.69 | ||
| Yes | 6 | 1.00 (0.85–1.19) | |
| No | 31 | 0.97 (0.90–1.04) | |
| Trial size | 0.66 | ||
| <200 patients per group | 20 | 0.98 (0.88–1.10) | |
| ≥200 patients per group | 17 | 0.96 (0.88–1.04) |
ITT, analysis according to the intention-to-treat principle.
Drug interventions include chondroitin, glucosamine, NSAIDs, opioids, paracetamol and viscosupplementation. Interventions in complementary medicine include acupuncture, balneotherapy, chondroitin and glucosamine.
ROR of 1 means no difference between approximated and observed odds ratios; ROR >1 means that the approximated odds ratio overestimates the observed treatment benefit; ROR<1 means that the approximated odds ratio underestimates the observed treatment benefit.
Approximated odds ratios were derived according to Hasselblad and Hedges method, using change from baseline values for the analysis.
Stratified analysis comparing approximated odds ratio based on Hasselblad and Hedges method to observed odds ratio
| Stratified analysis | Number of comparisons | ROR (95% CI) | P for interaction |
|---|---|---|---|
| Overall | 37 | 0.97 (0.91–1.04) | |
| Treatment effect size | 0.70 | ||
| Small | 29 | 0.96 (0.91–1.01) | |
| Large | 8 | 1.02 (0.77–1.35) | |
| Drug intervention | 0.89 | ||
| Yes | 33 | 0.97 (0.92–1.02) | |
| No | 4 | 1.00 (0.63–1.58) | |
| Complementary medicine | 0.97 | ||
| Yes | 10 | 0.97 (0.79–1.19) | |
| No | 27 | 0.97 (0.92–1.03) | |
| Concealment adequate | 0.98 | ||
| Yes | 14 | 0.99 (0.86–1.14) | |
| Unclear | 23 | 0.96 (0.89–1.03) | |
| Blinding patient and therapist adequate | 0.97 | ||
| Yes | 8 | 0.97 (0.86–1.11) | |
| No | 29 | 0.97 (0.90–1.05) | |
| ITT performed | 0.69 | ||
| Yes | 6 | 1.00 (0.85–1.19) | |
| No | 31 | 0.97 (0.90–1.04) | |
| Trial size | 0.66 | ||
| <200 patients per group | 20 | 0.98 (0.88–1.10) | |
| ≥200 patients per group | 17 | 0.96 (0.88–1.04) |
| Stratified analysis | Number of comparisons | ROR (95% CI) | P for interaction |
|---|---|---|---|
| Overall | 37 | 0.97 (0.91–1.04) | |
| Treatment effect size | 0.70 | ||
| Small | 29 | 0.96 (0.91–1.01) | |
| Large | 8 | 1.02 (0.77–1.35) | |
| Drug intervention | 0.89 | ||
| Yes | 33 | 0.97 (0.92–1.02) | |
| No | 4 | 1.00 (0.63–1.58) | |
| Complementary medicine | 0.97 | ||
| Yes | 10 | 0.97 (0.79–1.19) | |
| No | 27 | 0.97 (0.92–1.03) | |
| Concealment adequate | 0.98 | ||
| Yes | 14 | 0.99 (0.86–1.14) | |
| Unclear | 23 | 0.96 (0.89–1.03) | |
| Blinding patient and therapist adequate | 0.97 | ||
| Yes | 8 | 0.97 (0.86–1.11) | |
| No | 29 | 0.97 (0.90–1.05) | |
| ITT performed | 0.69 | ||
| Yes | 6 | 1.00 (0.85–1.19) | |
| No | 31 | 0.97 (0.90–1.04) | |
| Trial size | 0.66 | ||
| <200 patients per group | 20 | 0.98 (0.88–1.10) | |
| ≥200 patients per group | 17 | 0.96 (0.88–1.04) |
ITT, analysis according to the intention-to-treat principle.
Drug interventions include chondroitin, glucosamine, NSAIDs, opioids, paracetamol and viscosupplementation. Interventions in complementary medicine include acupuncture, balneotherapy, chondroitin and glucosamine.
ROR of 1 means no difference between approximated and observed odds ratios; ROR >1 means that the approximated odds ratio overestimates the observed treatment benefit; ROR<1 means that the approximated odds ratio underestimates the observed treatment benefit.
Approximated odds ratios were derived according to Hasselblad and Hedges method, using change from baseline values for the analysis.
Table 6 presents differences in approximated and observed risk differences across all trials for all methods. Again, confidence intervals overlapped widely. Except for Kraemer and Kupfer, all differences were negative with a τ2 of 0.00 and indicated that approximated risk differences were slightly more conservative than reported. The difference between risk differences as approximated by Kraemer and Kupfer and as observed was 4.8% (95% CI 2.3–7.3), reflecting an overestimation of the benefit of the experimental intervention; the corresponding τ2 was 0.01, and the 95% PI −16 to 25. Supplementary Appendix F shows differences in risk differences approximated from mean final values at follow-up. Figure 3 shows scatter plots comparing corresponding NNTs as observed on the x-axis with NNTs as approximated on the y-axis, for approximations derived from mean changes for all five methods. Agreement between observed and approximated NNTs as determined by ICC were again ≥0.90 for all methods, except for Kraemer and Kupfer’s (ICC = 0.73), which was inferior to the four other methods (P values for pairwise differences in ICC all ≤ 0.002). Kraemer and Kupfer’s method underestimated NNTs (hence showed overoptimistic effects) in case of an observed benefit of the experimental treatment and underestimated NNHs (hence showed overly pessimistic effects) in case of observed harm of the experimental treatment. Supplementary Appendix G presents scatter plots and ICCs for NNTs approximated from mean final values at follow-up.
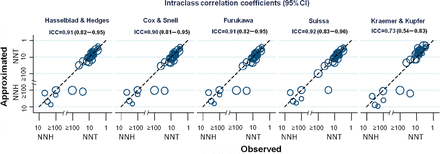
Scatter plots per conversion method showing the association between observed number needed to treat (x-axis) and approximated number needed to treat (y-axis) at the trial level. ICC, intraclass correlation coefficient; dashed lines indicate the line of identity between approximated and observed NNTs; estimates lying above the line of identity indicate that the approximated NNT overestimates the observed treatment benefit; estimates lying below the line of identity indicate that the approximated NNT underestimates the observed treatment benefit. Approximated NNTs were derived from change from baseline values; see Supplementary Appendix G for estimates based on final values at follow-up
Difference between approximated and observed risk differences according to each conversion method
| Method of conversion | DRD (95% CI) |
|---|---|
| Hasselblad and Hedges | −0.8% (−2.1 to 0.5) |
| Cox and Snell | −1.9% (−3.1 to −0.7) |
| Furukawa | −1.8% (−3.0 to −0.7) |
| Suissa | −1.7% (−2.8 to −0.6) |
| Kraemer and Kupfer | 4.8% (2.3 to 7.3) |
| Method of conversion | DRD (95% CI) |
|---|---|
| Hasselblad and Hedges | −0.8% (−2.1 to 0.5) |
| Cox and Snell | −1.9% (−3.1 to −0.7) |
| Furukawa | −1.8% (−3.0 to −0.7) |
| Suissa | −1.7% (−2.8 to −0.6) |
| Kraemer and Kupfer | 4.8% (2.3 to 7.3) |
DRD, difference in risk difference.
DRD of 0 means no difference between approximated and observed risk differences; DRD >0 means that the approximated risk difference overestimates the observed treatment response; DRD <0 means that the approximated risk difference underestimates the observed treatment response.
Approximated risk differences were derived from change from baseline values; see Supplementary Appendix F for estimates based on final values at follow-up.
Difference between approximated and observed risk differences according to each conversion method
| Method of conversion | DRD (95% CI) |
|---|---|
| Hasselblad and Hedges | −0.8% (−2.1 to 0.5) |
| Cox and Snell | −1.9% (−3.1 to −0.7) |
| Furukawa | −1.8% (−3.0 to −0.7) |
| Suissa | −1.7% (−2.8 to −0.6) |
| Kraemer and Kupfer | 4.8% (2.3 to 7.3) |
| Method of conversion | DRD (95% CI) |
|---|---|
| Hasselblad and Hedges | −0.8% (−2.1 to 0.5) |
| Cox and Snell | −1.9% (−3.1 to −0.7) |
| Furukawa | −1.8% (−3.0 to −0.7) |
| Suissa | −1.7% (−2.8 to −0.6) |
| Kraemer and Kupfer | 4.8% (2.3 to 7.3) |
DRD, difference in risk difference.
DRD of 0 means no difference between approximated and observed risk differences; DRD >0 means that the approximated risk difference overestimates the observed treatment response; DRD <0 means that the approximated risk difference underestimates the observed treatment response.
Approximated risk differences were derived from change from baseline values; see Supplementary Appendix F for estimates based on final values at follow-up.
Table 7 shows corresponding differences in NNTs between approximated estimates and the reported data of observed treatment response. Numerically, approximations according to Hasselblad and Hedges performed best, with a difference in NNTs of 0.5 (95% CI, −0.1 to 1.6). Confidence intervals between estimates were overlapping widely, however. Again, Kraemer and Kupfer’s approximation performed worst, with an overestimation of the treatment benefit, i.e. lower NNTs on average than actually observed. Supplementary Appendix H presents differences in NNTs approximated from mean final values at follow-up.
Difference between approximated and observed number needed to treat (NNT) according to each conversion method
| Method of conversion | Difference in NNT (95% CI) |
|---|---|
| Hasselblad and Hedges | 0.5 (−0.1 to 1.6) |
| Cox and Snell | 1.3 (0.4 to 2.1) |
| Furukawa | 0.9 (0.3 to 2.1) |
| Suissa | 0.5 (0.3 to 2.2) |
| Kraemer and Kupfer | −1.4 (−2.2 to −1.0) |
| Method of conversion | Difference in NNT (95% CI) |
|---|---|
| Hasselblad and Hedges | 0.5 (−0.1 to 1.6) |
| Cox and Snell | 1.3 (0.4 to 2.1) |
| Furukawa | 0.9 (0.3 to 2.1) |
| Suissa | 0.5 (0.3 to 2.2) |
| Kraemer and Kupfer | −1.4 (−2.2 to −1.0) |
Positive differences mean that the approximated NNT underestimates the observed treatment benefit, and negative differences mean that the approximated NNT overestimates the observed treatment benefit.
Approximated NNTs were derived from change from baseline values; see Supplementary Appendix H for estimates based on final values at follow-up.
Difference between approximated and observed number needed to treat (NNT) according to each conversion method
| Method of conversion | Difference in NNT (95% CI) |
|---|---|
| Hasselblad and Hedges | 0.5 (−0.1 to 1.6) |
| Cox and Snell | 1.3 (0.4 to 2.1) |
| Furukawa | 0.9 (0.3 to 2.1) |
| Suissa | 0.5 (0.3 to 2.2) |
| Kraemer and Kupfer | −1.4 (−2.2 to −1.0) |
| Method of conversion | Difference in NNT (95% CI) |
|---|---|
| Hasselblad and Hedges | 0.5 (−0.1 to 1.6) |
| Cox and Snell | 1.3 (0.4 to 2.1) |
| Furukawa | 0.9 (0.3 to 2.1) |
| Suissa | 0.5 (0.3 to 2.2) |
| Kraemer and Kupfer | −1.4 (−2.2 to −1.0) |
Positive differences mean that the approximated NNT underestimates the observed treatment benefit, and negative differences mean that the approximated NNT overestimates the observed treatment benefit.
Approximated NNTs were derived from change from baseline values; see Supplementary Appendix H for estimates based on final values at follow-up.
Table 8 presents pooled odds ratios (top) and NNTs (bottom) as calculated from reported data of observed treatment response and approximated from SMDs for meta-analyses on the seven interventions with at least two trials included in our study: NSAIDS (6 trials, 10 comparisons, 3127 patients), topical NSAIDs (2 trials, 2 comparisons, 708 patients), food supplement (2 trials, 4 comparisons, 1887 patients), acupuncture (2 trials, 2 comparisons, 1409 patients), opioids (5 trials, 5 comparisons, 2014 patients), SNRIs (2 trials, 2 comparisons, 475 patients), viscosupplementation (7 trials, 7 comparisons, 2640 patients). All five methods performed well, including Kraemer and Kupfer’s.7
Odds ratio and number needed to treat according to type of intervention and conversion method based on summary SMD
| Odds ratio (OR) | NSAIDs OR (95% CI) | Topical NSAIDs OR (95% CI) | Food supplement OR (95% CI) | Acupuncture OR (95% CI) | Opioids OR (95% CI) | SNRIs OR (95% CI) | Viscosupplementation OR (95% CI) |
|---|---|---|---|---|---|---|---|
| Observed treatment response | 2.3 (1.8–2.9) | 1.8 (1.2–2.6) | 1.2 (1.0–1.4) | 2.9 (0.4–19) | 1.8 (1.5–2.2) | 1.4 (0.6–3.2) | 1.5 (1.0–2.1) |
| Hasselblad and Hedges | 2.2 (1.7–2.8) | 1.9 (1.4–2.5) | 1.2 (0.9–1.6) | 2.3 (0.6–8.3) | 1.7 (1.5–2.0) | 1.3 (0.5–3.5) | 1.5 (1.0–2.2) |
| Cox and Snell | 2.1 (1.7–2.5) | 1.8 (1.4–2.3) | 1.2 (0.9–1.5) | 2.1 (0.6–6.9) | 1.6 (1.4–1.9) | 1.2 (0.5–3.2) | 1.4 (1.0–2.0) |
| Furukawa | 2.0 (1.6–2.5) | 1.7 (1.4–2.2) | 1.2 (0.9–1.5) | 2.1 (0.6–6.8) | 1.6 (1.4–1.9) | 1.2 (0.5–3.1) | 1.4 (1.0–2.0) |
| Suissa | 2.1 (1.7–2.6) | 1.8 (1.3–2.4) | 1.2 (0.9–1.4) | 2.2 (0.6–7.4) | 1.7 (1.4–2.0) | 1.3 (0.5–3.2) | 1.5 (1.0–2.2) |
| Kraemer and Kupfer | 2.7 (2.0–3.7) | 2.2 (1.6–3.1) | 1.3 (0.9–1.8) | 2.8 (0.5–87) | 2.0 (1.6–2.4) | 1.4 (0.3–5.2) | 1.6 (1.0–2.7) |
| Odds ratio (OR) | NSAIDs OR (95% CI) | Topical NSAIDs OR (95% CI) | Food supplement OR (95% CI) | Acupuncture OR (95% CI) | Opioids OR (95% CI) | SNRIs OR (95% CI) | Viscosupplementation OR (95% CI) |
|---|---|---|---|---|---|---|---|
| Observed treatment response | 2.3 (1.8–2.9) | 1.8 (1.2–2.6) | 1.2 (1.0–1.4) | 2.9 (0.4–19) | 1.8 (1.5–2.2) | 1.4 (0.6–3.2) | 1.5 (1.0–2.1) |
| Hasselblad and Hedges | 2.2 (1.7–2.8) | 1.9 (1.4–2.5) | 1.2 (0.9–1.6) | 2.3 (0.6–8.3) | 1.7 (1.5–2.0) | 1.3 (0.5–3.5) | 1.5 (1.0–2.2) |
| Cox and Snell | 2.1 (1.7–2.5) | 1.8 (1.4–2.3) | 1.2 (0.9–1.5) | 2.1 (0.6–6.9) | 1.6 (1.4–1.9) | 1.2 (0.5–3.2) | 1.4 (1.0–2.0) |
| Furukawa | 2.0 (1.6–2.5) | 1.7 (1.4–2.2) | 1.2 (0.9–1.5) | 2.1 (0.6–6.8) | 1.6 (1.4–1.9) | 1.2 (0.5–3.1) | 1.4 (1.0–2.0) |
| Suissa | 2.1 (1.7–2.6) | 1.8 (1.3–2.4) | 1.2 (0.9–1.4) | 2.2 (0.6–7.4) | 1.7 (1.4–2.0) | 1.3 (0.5–3.2) | 1.5 (1.0–2.2) |
| Kraemer and Kupfer | 2.7 (2.0–3.7) | 2.2 (1.6–3.1) | 1.3 (0.9–1.8) | 2.8 (0.5–87) | 2.0 (1.6–2.4) | 1.4 (0.3–5.2) | 1.6 (1.0–2.7) |
| Number needed to treat (NNT) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) |
|---|---|---|---|---|---|---|---|
| Observed treatment response | 5 (4–7) | 6 (3–62) | 24 (12–435) | 2 (0–∞) | 7 (5–11) | 11 (2–∞) | 10 (5–2392) |
| Hasselblad and Hedges | 5 (4–7) | 6 (5–11) | 21 (8–∞) | 5 (2–∞) | 7 (6–11) | 17 (3–∞) | 10 (5–∞) |
| Cox and Snell | 6 (4–8) | 7 (5–13) | 23 (9–∞) | 5 (2–∞) | 8 (6–12) | 19 (4–∞) | 12 (6–∞) |
| Furukawa | 6 (4–8) | 7 (5–13) | 24 (10–∞) | 6 (2–∞) | 8 (6–12) | 19 (4–∞) | 12 (6–∞) |
| Suissa | 5 (3–7) | 5 (3–11) | 26 (10–∞) | 3 (1–∞) | 8 (5–15) | 16 (3–∞) | 10 (4–∞) |
| Kraemer and Kupfer | 4 (3–6) | 5 (4–9) | 16 (7–∞) | 4 (2–∞) | 6 (5–9) | 13 (3–∞) | 8 (4–∞) |
| Number needed to treat (NNT) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) |
|---|---|---|---|---|---|---|---|
| Observed treatment response | 5 (4–7) | 6 (3–62) | 24 (12–435) | 2 (0–∞) | 7 (5–11) | 11 (2–∞) | 10 (5–2392) |
| Hasselblad and Hedges | 5 (4–7) | 6 (5–11) | 21 (8–∞) | 5 (2–∞) | 7 (6–11) | 17 (3–∞) | 10 (5–∞) |
| Cox and Snell | 6 (4–8) | 7 (5–13) | 23 (9–∞) | 5 (2–∞) | 8 (6–12) | 19 (4–∞) | 12 (6–∞) |
| Furukawa | 6 (4–8) | 7 (5–13) | 24 (10–∞) | 6 (2–∞) | 8 (6–12) | 19 (4–∞) | 12 (6–∞) |
| Suissa | 5 (3–7) | 5 (3–11) | 26 (10–∞) | 3 (1–∞) | 8 (5–15) | 16 (3–∞) | 10 (4–∞) |
| Kraemer and Kupfer | 4 (3–6) | 5 (4–9) | 16 (7–∞) | 4 (2–∞) | 6 (5–9) | 13 (3–∞) | 8 (4–∞) |
Analysis is based on change from baseline values.
CI, confidence interval; NSAID, nonsteroidal antiinflamatory drug; SNRI, serotonin and norepinephrine reuptake inhibitor.
Odds ratio and number needed to treat according to type of intervention and conversion method based on summary SMD
| Odds ratio (OR) | NSAIDs OR (95% CI) | Topical NSAIDs OR (95% CI) | Food supplement OR (95% CI) | Acupuncture OR (95% CI) | Opioids OR (95% CI) | SNRIs OR (95% CI) | Viscosupplementation OR (95% CI) |
|---|---|---|---|---|---|---|---|
| Observed treatment response | 2.3 (1.8–2.9) | 1.8 (1.2–2.6) | 1.2 (1.0–1.4) | 2.9 (0.4–19) | 1.8 (1.5–2.2) | 1.4 (0.6–3.2) | 1.5 (1.0–2.1) |
| Hasselblad and Hedges | 2.2 (1.7–2.8) | 1.9 (1.4–2.5) | 1.2 (0.9–1.6) | 2.3 (0.6–8.3) | 1.7 (1.5–2.0) | 1.3 (0.5–3.5) | 1.5 (1.0–2.2) |
| Cox and Snell | 2.1 (1.7–2.5) | 1.8 (1.4–2.3) | 1.2 (0.9–1.5) | 2.1 (0.6–6.9) | 1.6 (1.4–1.9) | 1.2 (0.5–3.2) | 1.4 (1.0–2.0) |
| Furukawa | 2.0 (1.6–2.5) | 1.7 (1.4–2.2) | 1.2 (0.9–1.5) | 2.1 (0.6–6.8) | 1.6 (1.4–1.9) | 1.2 (0.5–3.1) | 1.4 (1.0–2.0) |
| Suissa | 2.1 (1.7–2.6) | 1.8 (1.3–2.4) | 1.2 (0.9–1.4) | 2.2 (0.6–7.4) | 1.7 (1.4–2.0) | 1.3 (0.5–3.2) | 1.5 (1.0–2.2) |
| Kraemer and Kupfer | 2.7 (2.0–3.7) | 2.2 (1.6–3.1) | 1.3 (0.9–1.8) | 2.8 (0.5–87) | 2.0 (1.6–2.4) | 1.4 (0.3–5.2) | 1.6 (1.0–2.7) |
| Odds ratio (OR) | NSAIDs OR (95% CI) | Topical NSAIDs OR (95% CI) | Food supplement OR (95% CI) | Acupuncture OR (95% CI) | Opioids OR (95% CI) | SNRIs OR (95% CI) | Viscosupplementation OR (95% CI) |
|---|---|---|---|---|---|---|---|
| Observed treatment response | 2.3 (1.8–2.9) | 1.8 (1.2–2.6) | 1.2 (1.0–1.4) | 2.9 (0.4–19) | 1.8 (1.5–2.2) | 1.4 (0.6–3.2) | 1.5 (1.0–2.1) |
| Hasselblad and Hedges | 2.2 (1.7–2.8) | 1.9 (1.4–2.5) | 1.2 (0.9–1.6) | 2.3 (0.6–8.3) | 1.7 (1.5–2.0) | 1.3 (0.5–3.5) | 1.5 (1.0–2.2) |
| Cox and Snell | 2.1 (1.7–2.5) | 1.8 (1.4–2.3) | 1.2 (0.9–1.5) | 2.1 (0.6–6.9) | 1.6 (1.4–1.9) | 1.2 (0.5–3.2) | 1.4 (1.0–2.0) |
| Furukawa | 2.0 (1.6–2.5) | 1.7 (1.4–2.2) | 1.2 (0.9–1.5) | 2.1 (0.6–6.8) | 1.6 (1.4–1.9) | 1.2 (0.5–3.1) | 1.4 (1.0–2.0) |
| Suissa | 2.1 (1.7–2.6) | 1.8 (1.3–2.4) | 1.2 (0.9–1.4) | 2.2 (0.6–7.4) | 1.7 (1.4–2.0) | 1.3 (0.5–3.2) | 1.5 (1.0–2.2) |
| Kraemer and Kupfer | 2.7 (2.0–3.7) | 2.2 (1.6–3.1) | 1.3 (0.9–1.8) | 2.8 (0.5–87) | 2.0 (1.6–2.4) | 1.4 (0.3–5.2) | 1.6 (1.0–2.7) |
| Number needed to treat (NNT) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) |
|---|---|---|---|---|---|---|---|
| Observed treatment response | 5 (4–7) | 6 (3–62) | 24 (12–435) | 2 (0–∞) | 7 (5–11) | 11 (2–∞) | 10 (5–2392) |
| Hasselblad and Hedges | 5 (4–7) | 6 (5–11) | 21 (8–∞) | 5 (2–∞) | 7 (6–11) | 17 (3–∞) | 10 (5–∞) |
| Cox and Snell | 6 (4–8) | 7 (5–13) | 23 (9–∞) | 5 (2–∞) | 8 (6–12) | 19 (4–∞) | 12 (6–∞) |
| Furukawa | 6 (4–8) | 7 (5–13) | 24 (10–∞) | 6 (2–∞) | 8 (6–12) | 19 (4–∞) | 12 (6–∞) |
| Suissa | 5 (3–7) | 5 (3–11) | 26 (10–∞) | 3 (1–∞) | 8 (5–15) | 16 (3–∞) | 10 (4–∞) |
| Kraemer and Kupfer | 4 (3–6) | 5 (4–9) | 16 (7–∞) | 4 (2–∞) | 6 (5–9) | 13 (3–∞) | 8 (4–∞) |
| Number needed to treat (NNT) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) | NNT (95% CI) |
|---|---|---|---|---|---|---|---|
| Observed treatment response | 5 (4–7) | 6 (3–62) | 24 (12–435) | 2 (0–∞) | 7 (5–11) | 11 (2–∞) | 10 (5–2392) |
| Hasselblad and Hedges | 5 (4–7) | 6 (5–11) | 21 (8–∞) | 5 (2–∞) | 7 (6–11) | 17 (3–∞) | 10 (5–∞) |
| Cox and Snell | 6 (4–8) | 7 (5–13) | 23 (9–∞) | 5 (2–∞) | 8 (6–12) | 19 (4–∞) | 12 (6–∞) |
| Furukawa | 6 (4–8) | 7 (5–13) | 24 (10–∞) | 6 (2–∞) | 8 (6–12) | 19 (4–∞) | 12 (6–∞) |
| Suissa | 5 (3–7) | 5 (3–11) | 26 (10–∞) | 3 (1–∞) | 8 (5–15) | 16 (3–∞) | 10 (4–∞) |
| Kraemer and Kupfer | 4 (3–6) | 5 (4–9) | 16 (7–∞) | 4 (2–∞) | 6 (5–9) | 13 (3–∞) | 8 (4–∞) |
Analysis is based on change from baseline values.
CI, confidence interval; NSAID, nonsteroidal antiinflamatory drug; SNRI, serotonin and norepinephrine reuptake inhibitor.
Discussion
In this meta-epidemiological study of 37 randomized comparisons from 29 large-scale osteoarthritis trials in 13 654 patients, we found four4-6,13 out of five methods suitable for responder analyses, converting differences in means of pain intensity or global symptom severity between treatment groups into odds ratios of treatment response and NNT at the level of randomized trials. When comparing estimates calculated from reported data of observed treatment response with approximated estimates, we found that approximated estimates tended to be slightly more conservative than observed estimates for all methods, except for the approach suggested by Kraemer and Kupfer7: approximated odds ratios were 3–8% more conservative on average for these methods4-6,13 than odds ratios of observed treatment response. The method suggested by Kraemer and Kupfer7 resulted in an overestimation of treatment benefits and appeared unsuitable for responder analyses.
What does this mean for a specific clinical trial? In the trial by Gana et al.,23–25 for example, which shows results much in line with overall estimates, the odds ratio of treatment response comparing tramadol 200 mg daily with placebo was 2.0 (95% CI, 1.3–2.9) as calculated from reported data on treatment response, and 1.8 (95% CI, 1.3–2.6) as approximated from differences in pain intensity measured on a 100-mm visual analogue scale according to Hasselblad and Hedges.4 This translated into an NNT of six patients to be treated with tramadol to achieve an additional treatment response as compared with placebo when directly calculated from reported data, and an NNT of seven when approximated from differences in pain intensity, both estimates again clinically equivalent. Only for two trials, we found discrepancies that might lead to differing inferences.26,27 Both trials evaluated unconventional interventions, one found an unusually large treatment benefit compared with placebo,27 the other a large benefit compared with a non-intervention control.26 When excluding these two trials from the analysis, we found τ2 estimates to decrease by ∼40% (data available on request).
At the level of meta-analyses, random variation was even smaller and approximated odds ratios and NNT were much the same as estimates calculated from reported data of observed treatment response, irrespective of the method used. Even the method by Kraemer and Kupfer, which performed unsatisfactorily on trial level, performed reasonably well. In one meta-analysis, however, the four methods that usually performed well on trial level4-6,13 showed discrepancies that could result in misleading impressions of the magnitude of effect. This meta-analysis addressed acupuncture and included only two trials (see Figure 1); one found a small effect as compared with a sham intervention,28 the other an unusually large benefit compared with non-intervention control.26
Stratified analyses according to baseline risk of treatment response suggested that all four suitable methods4-6,13 may be somewhat too conservative for control group response rates of ≤20% and somewhat too optimistic for rates >60%, but rates of ≤20% or >60% were observed in only few trials, and confidence intervals were wide and tests for interaction all negative. Similarly, in stratified analyses according to the stringency of cut-off scores to define treatment response, we did not find any evidence for differences in performance of these methods.4-6,13 For Kraemer and Kupfer’s approach we found evidence that overestimations of treatment benefits increased with decreasing baseline risk of treatment response. Overestimations became particularly pronounced at baseline risks of ≤40%. As baseline risk is partially a function of the definition of treatment response, it is unsurprising that the extent of overestimation for Kraemer and Kupfer’s method tended to be associated with the cut-off scores used to define treatment response.
A wide range of instruments was used to measure pain or global symptoms, and only for pain overall measured on a visual analogue scale, patient global assessment and the WOMAC pain subscale we found a sufficient number of trials to allow precise estimates; again, we did not find evidence to suggest differences in performance across instruments. Stratified analyses according to trial characteristics were performed for Hasselblad and Hedges’ method only and did not suggest differences in performance of the approximations depending on these characteristics.
Our study is the most comprehensive empirical evaluation of the performance of methods used to convert continuous outcomes into odds ratios of treatment response and NNT or harm to date. As calculations of NNTs are based on risk differences, our results are also applicable to this measure of treatment benefit. The study was based on all large-scale randomized trials published as English full-text article since 1980 as identified in a systematic search of the Cochrane Central Register of Controlled Trials, which compared any intervention with placebo or non-intervention control in patients with osteoarthritis of the knee or hip and provided data on both, continuous pain or symptom severity and dichotomized treatment response. Our results may apply not only to osteoarthritis, but also to other clinical areas, particularly if scores on symptom severity are analysed, with a defined restricted range of possible scores (e.g. 0–100 mm on a visual analogue scale). This will be true if the clinical heterogeneity of patients enrolled is similar from trial to trial and not extremely homogeneous or heterogeneous, and if results approximately follow a normal distribution. Examples in which these conditions are likely to be met include depression and asthma. For outcomes that are not based on formal symptom scoring, such as blood pressure measurements in patients with arterial hypertension or walking distance in patients with intermittent claudication, the distribution of collected data is not restricted per se and skewed data could result in substantial discrepancies. Indeed, Anzures-Cabrera et al. found in a simulation study that most methods will result in inaccurate estimates if data are skewed or standard deviations differ substantially across treatment groups.14 To minimize the influence of small study effects due to selective reporting and publication and low methodological quality of small trials, we restricted our sample to trials that enrolled 100 patients per group.29 Our results may, therefore, not apply for single small-scale trials, as simulations from Anzures-Cabrera et al. suggest.14 When conversion methods are used in a meta-analysis of multiple trials, with an accumulated number of patients of several hundreds to a few thousands,11 this limitation will not apply.
In 2005, Furukawa et al.16 determined the performance of their own approximation method using data from 4 meta-analyses of 47 trials in 4540 patients with depression or panic disorder. Approximated risk ratios of treatment response were much the same as estimates calculated from observed treatment response, albeit slightly more conservative, as observed in our study. Furukawa and Leucht8 subsequently determined the performance of their own method as compared with Kraemer and Kupfer’s in approximating NNTs in four meta-analyses, including 10 trials of second-generation anti-psychotics in 4278 patients with schizophrenia. Consistent with our results, they found Furukawa’s method more accurate than Kraemer and Kupfer’s. If definitions of treatment response required a change in symptom severity of <80%, Furukawa’s approximation yielded NNTs that were only slightly more conservative than observed. For more stringent definitions of treatment response, with required changes from baseline of ≥80%, Furukawa’s method became unacceptably conservative. Kraemer and Kupfer’s approximation was always overoptimistic and deviated more from observed estimates with more extreme definitions of treatment response, as was the case in our study (Table 3). Comparisons of statistical methods typically involve three steps: statistical theory, simulation studies and empirical evaluations in real-world datasets. Anzures-Cabrera et al.14 compared the methods by Hasselblad and Hedges,4 Cox and Snell5 and Suissa6 based on statistical theory and a comprehensive simulation study, and empirically determined their performance in a convenience sample of 16 trials with 2247 patients with Alzheimer dementia or anxiety disorders. As in our study, approximated odds ratios were similar and slightly more conservative than the odds ratio of observed treatment success, with Hasselblad and Hedges’ approximation being closest to the observed estimate. We believe that our study complements and extends on these studies. It compares all five methods available to date, empirically evaluates these methods in a larger dataset of 29 trials with 13 654 patients, is based on a systematic search of the literature and covers a different clinical condition.
Recent guidelines on assessment of chronic pain30,31 and osteoarthritis,32 as well as the US Food and Drug Administration,33 suggest the use of responder analyses to facilitate interpretability of treatment effects measured on a continuous scale. For the purpose of this report, we presented the performance of currently available methods to approximate comparisons of responders between groups on odds ratio, NNT and risk difference scales. However, all four methods that performed well on these scales perform equally well on a risk ratio scale (data available on request). As Hasselblad and Hedges’ and Cox and Snell’s conversion methods directly yield odds ratios, whereas Furukawa’s and Suissa’s approaches yield group specific risks, the investigators’ preferred scale to express treatment effects may guide the selection of conversion method.
Funding
This project was funded by the ARCO Foundation, Switzerland.
Acknowledgements
We thank Marcel Zwahlen and Thomas Gsponer for helpful comments and Shelagh Redmond and Pippa Scott for support in database development.
Conflict of interest: None declared.
Clinicians find standardized mean differences calculated from continuous outcomes difficult to interpret.
Standardized mean differences and means can be converted into odds ratios of treatment response and numbers needed to treat as more intuitive measures of treatment effect.
Currently the methods described by Hasselblad and Hedges, Cox and Snell, Furukawa and Suissa are suitable to convert summary treatment effects calculated from continuous outcomes into odds ratios of treatment response and numbers needed to treat.


{kind=link}
{kind=link}
{kind=link}